
LLM の頭の中を覗いたとき、意味はどんな形で表現されているのでしょうか。本レポートでは、線形表現仮説 (Linear Representation Hypothesis, LRH) を巡る Park 論文と Golechha ブログという対立軸を、4 モデル × 30 seed の系統的な再現実験で確かめます。日本語 WordNet × LLM-jp-4-8B への拡張、および Park の 70% 独立サブサンプル診断の定量化が本実験の独自部分です。結論を先取りすると、near-zero cosine だけでは Golechha の言うとおり証拠不足ですが、Park の追加診断(独立サブサンプル)には trained unembedding に残る構造を捉える力もありそうだ、という両論併記的な着地になります。
第1章. はじめに
LLM の頭の中を覗いたとき、意味はどんな形で表現されているのでしょうか。これは interpretability 研究で長く問われてきたテーマで、重要な問いです。実際、Anthropic が 2026 年 4 月に preview 公開した Claude Mythos のように LLM の能力は急速に高まり、サイバーセキュリティを含む高度な領域でも実用に踏み込むなかで、その内部を部品レベルで読み解くこと——機械論的解釈可能性 (mechanistic interpretability) と呼ばれる研究領域——は AI 安全性 (safety) と アライメント (alignment) の核心になっています。
なかでも本レポートが扱う 幾何的解釈——内部状態という高次元ベクトル空間に意味の構造がどう埋め込まれているかを読み解く方向性——はその基礎にあたります。出発点となる仮説が、本レポートの中心テーマである 線形表現仮説 (Linear Representation Hypothesis, LRH)——「概念はベクトル空間の方向として表現される」というシンプルな見方——です。
例として有名なのが、word2vec で見つかった次の不思議な等式です。
v(king) - v(man) + v(woman) ≈ v(queen)
「男性 → 女性」という意味の変換が、ベクトル空間上の一定の方向として現れている、と読めます。LLM の内部にも、こうした「意味の方向性」がもっと豊かな形で住んでいるのではないか——これが LRH の中心的な問いです。
線形表現仮説の到達点と限界
LRH はここ十数年で大きく形を変え、Transformer ベースの LLM では residual stream(各層を貫く情報の流れ)にいろいろな意味的特徴が方向として埋め込まれていることが、2023 年頃の実証研究で次々と確認されてきました。Othello-GPT で世界モデル、推論時介入 (ITI) で真実性、対比一致探索 (CCS) で真理方向といった具合です。これらの詳しい流れは第 2 章のタイムラインで振り返ります。
実応用の側でも、LRH は近年の interpretability ツールの基盤として中心的な役割を果たしています。たとえば スパースオートエンコーダ (Sparse Autoencoder, SAE) を使った特徴の分解は「特徴は方向として表現されている」という前提に依存していますし、表現エンジニアリング (representation engineering)(活性化編集による振る舞い制御)も「ある概念に対応する方向ベクトルを足し引きすれば出力が動く」という LRH の系として読めます。LLM の中身を覗き、操作するための共通語彙として、LRH は今や interpretability の土台と言ってよい立ち位置にあります。
それでも LRH には限界もあります。たとえば曜日や月のような周期的な概念は一次元の方向ではなく二次元の円として表現されるという反例 (Engels et al., 2024) もありますし、そもそも「方向=意味」と素朴に対応づけてよいか、観察された幾何が本物か高次元のあやか、という問いも残っています。
LRH の到達点と限界を考える上で、最近とくに参照する価値が高い 2 件の文献があります。それが本レポートの軸になる Park 論文と Golechha ブログです。
なぜ Park 論文と Golechha ブログを取り上げるのか
ひとつは Park らによる 2 本の論文です。
- Park, Choe, Veitch (2023). The Linear Representation Hypothesis and the Geometry of Large Language Models(ICML 2024、約 632 引用)
- Park, Choe, Jiang, Veitch (2024). The Geometry of Categorical and Hierarchical Concepts in Large Language Models(ICLR 2025、約 160 引用)
Park らはまず 2023 年の論文で、それまで直観的に語られてきた LRH に数学的な足場を与えました。続く 2024 年の論文では、その足場の上に**「カテゴリ概念は多面体 (polytope)、階層関係は直交性として表現される」**という非常に踏み込んだ主張を出しています。LLM の表現幾何という話題で、Park 論文は今、最も強い存在感を持つ仕事のひとつです。
もうひとつは、Park の主張に正面から異議を唱えた Golechha ら (2025) の ICLR Blogposts 記事 Intricacies of Feature Geometry in Large Language Models です。ピアレビュー付き、Best Blog Award Runner-up にも選ばれた批評記事で、彼らはこう問いかけます——「Park の図、本当に意味階層を見ているのか?意味的にめちゃくちゃなデータでも、同じような図が描けてしまうのではないか」。
線形表現仮説の到達点と限界を考えるとき、Park の踏み込んだ主張と Golechha の鋭い反論をペアで読むのは最良のスタート地点になります。Park は LRH を「どこまで強く言えるか」を定式化し、Golechha はその主張のどこが脆弱かを攻めている。両方を並べて読むと、LRH が「どこまで言えて、どこから疑うべきか」が立体的に見えてきます。
本レポートでやってみたこと
既存実験を真似るだけでは面白くないので、本実験では次の点を独自に追加しました。
- 日本語 WordNet への拡張: Park の公式実験は英語のみ。本実験では Open Multilingual WordNet の日本語 lemma から Japanese WordNet mapping を作って、LLM-jp-4-8B(日本語モデル)でも同じ診断を走らせました。
- 4 モデル横断比較: Park の使った Gemma + LLaMA に Qwen3.5-2B と LLM-jp を加えた 4 モデル。系列の違うモデルでも同じ現象が見えるかを確認しました。
- Park の 70% 独立サブサンプル診断を定量化: Park 論文 Fig 5 で Gemma-2B 単独・視覚比較として提示されているこの診断を、本実験では
B4(サブサンプル単独)とB5(サブサンプル + シャッフル)として組み込み、4 モデル × 3 データセット × 30 seed で平均と 95% 信頼区間つきの定量比較に拡張しました(Golechha はこの診断を取り上げていません)。
先取りすると、結果は両論併記的なものになりました。near-zero cosine だけでは Golechha の言うとおり証拠不足ですが、Park の追加診断(独立サブサンプル)には trained unembedding に残る構造を捉える力もありそうだ、というところに着地します。
第2章. 線形表現仮説のタイムライン
LRH は、ある日突然提案された理論ではなく、十数年かけて少しずつ形になってきた考え方です。本章ではその流れを 6 段階に分けて、ざっくり振り返ります。
単語埋め込みの時代 (2013--2014)
話は 2013 年の Mikolov らの word2vec から始まります。「king から man を引いて woman を足すと queen になる」という有名な類推がベクトル空間の中で成り立つことが報告され、意味の変換が「方向」として現れているように見える、という驚きとともに広まりました。翌年、Pennington らの GloVe は、単語共起行列の分解という別の手法でも同様の線形構造が出ることを示します。ニューラルネットに固有の現象ではなく、もっと普遍的な何かを反映しているらしい——という見方が育ち始めたのがこの時期です。
「方向=概念」を測る方法論 (2017--2019)
2017 年前後から、深層学習モデルの中身を覗くための道具立てが揃ってきます。Alain & Bengio (2017) の線形プローブは、各層の活性化に線形分類器を当てはめてその精度を見ることで「ある概念が線形に取り出せるか」を測る方法を体系化し、以後 LRH 検証のデファクトスタンダードになりました。Hewitt & Manning (2019) はこの考え方を構文構造にまで拡げ、依存構造木が BERT の中間層から線形変換だけで復元できることを示しています。並行して、Kim ら (2018) の 概念活性化ベクトルによるテスト (TCAV) は別の角度から同じ問いに迫ります——ある概念の例を集めてその方向ベクトルを推定し、その方向への感度でモデルの判断を説明する、というアプローチで、「方向=概念」を操作的に定義しました。
幾何の側面に直接踏み込んだのが Reif ら (2019) の Visualizing and Measuring the Geometry of BERT です。BERT の内部表現を可視化し、構文や word sense(多義語の意味区別)が幾何的に分離されていることを示した代表的な仕事で、「方向=意味」の見方を Transformer 内部の幾何の話として展開する流れを作りました。
Transformer 時代と superposition (2021--2023)
LLM が Transformer ベースに移ると、興味の対象は単語埋め込みから残差ストリーム (residual stream)(各層を貫く情報の流れ)へと移ります。感情、拒否、真偽、文法属性といった特徴が、残差ストリームの中に方向として埋め込まれているのではないか、という見方が広がりました。
理論的な背景を与えたのが Elhage ら (2022) の Toy Models of Superposition です。ニューロン数より多い特徴を扱うときモデルは特徴を**重ね合わせ (superposition)**して表現する——という観察は、「方向=特徴」という考え方に自然な動機を提供しました。同時期の Olsson ら (2022) の In-context Learning and Induction Heads は、Transformer 内部の特定の注意ヘッドが「過去の系列を引いてきて出力する」回路として機能することを示しました。
実証面では、Meng ら (2022) の Locating and Editing Factual Associations in GPT (ROME) が、特定の事実知識を担う MLP 層の重みを直接編集することで、事実知識への直接介入を成功させました。続いて Turner ら (2023) の 活性化加算 (activation addition) や ステアリング (steering) は、内部状態にある方向ベクトルを足し込むだけで出力傾向が動くことを示します。
LRH の実証ラッシュ (2023)
2023 年は LRH にとって「実証の年」でした。Li ら (2023a) の Othello-GPT は、Othello の手筋だけを学習させた小型 Transformer の内部にボード上のコマの状態が線形に表現されていることを示し、合成的な制御環境での代表例となりました。Gurnee & Tegmark (2023) はもっと自然な領域に踏み込み、LLM の内部から地理座標と時間情報が線形にデコードできることを示して、「LLM は世界モデルを持つ」という議論の主要な根拠を与えました。実用面では Li ら (2023b) の 推論時介入 (Inference-Time Intervention, ITI) が際立ちます。「真実性」方向への内部状態シフトで Alpaca の TruthfulQA 正答率を 32.5% から 65.1% へと引き上げ、LRH が美しい現象だけでなく実用的な道具にもなることを示しました。Burns ら (2023) の 対比一致探索 (CCS) は教師なしで真理方向を発見する手法を提案し、6 モデル・10 データセットで一貫して機能することを示しています。
もう一つ、この時期に立ち上がった重要な流れが スパースオートエンコーダ (SAE) による特徴分解です。Cunningham ら (2023) と、ほぼ同時期に Bricken ら (2023) が Anthropic から発表した Towards Monosemanticity が、residual stream を SAE で再構成すると、解釈可能で単義的な特徴が大量に取り出せることを示しました。
形式化と限界画定 (2023--2024)
実証が積み重なるにつれ、「方向」「概念」「因果性」という言葉を厳密に扱う形式化が必要になってきます。Park ら (2023) は、二値概念を反事実的なペアで定義し直し、白色化された unembedding 空間(因果内積)という道具を導入することで、LRH に確かな数学的足場を与えました。続く Park ら (2024) は、これを多値カテゴリと階層関係に拡張し、「方向」を「複数の頂点を持つ図形」と「親子関係の直交性」へと一般化しています。本レポートの第 3 章以降の主題は、この拡張版の方です。
形式化と並行して、LRH を主張する手続きも標準化されていきます。Marks & Tegmark (2024) の Geometry of Truth は、可視化、別ドメインへの汎化、因果介入による出力変化、という三重の証拠を一貫した枠組みで示し、LRH 実証の方法論的な金字塔となりました。スケールの面では、Templeton ら (2024) の Scaling Monosemanticity (Anthropic) が、Claude 3 Sonnet 上で SAE を動かし、3,400 万規模の解釈可能な特徴を抽出してみせました。
ただし、すべてが線形に収まるわけではありません。Engels ら (2024) は、曜日や月のような周期的な概念が一次元の方向ではなく二次元の円として表現されることを示し、LRH の重要な「弱い反例」を提示しました。
統計的対称性からの理論的裏付け (2026)
ここまでの研究はどれも「LRH が成り立っているように見える」という観察を積み上げてきましたが、なぜそうなるのか、なぜ Engels の例のような例外があるのか、という理論的な根拠は長く宿題として残っていました。
Karkada ら (2026) の Symmetry in Language Statistics Shapes the Geometry of Model Representations は、その宿題への直接の答えを提示します。彼らの主張は、言語データの統計的対称性が学習されたモデルの表現幾何を直接形作る、というものです。さらに「ある特徴が一次元の線形方向として表現されるための必要十分条件」までが、対称性の言葉で書き下せます。曜日や月が円になるのは、それらが本質的に巡回的対称性を持つから、というわけです。
第3章. Park 論文と本再現実験
ここから本題の Park 論文に入ります。
Park 論文の主な主張
Park 論文 (2024) の中心的な主張は、ひとことで言うとこうです。
LLM が学習した unembedding 空間の中には、人間が WordNet で整理しているような意味の階層が、ある程度きれいに対応する形で埋め込まれている。具体的には、上位概念と下位概念は「直交した方向」として、同じカテゴリに属する値は「多面体 (polytope) の頂点」として、整然と並んでいる。
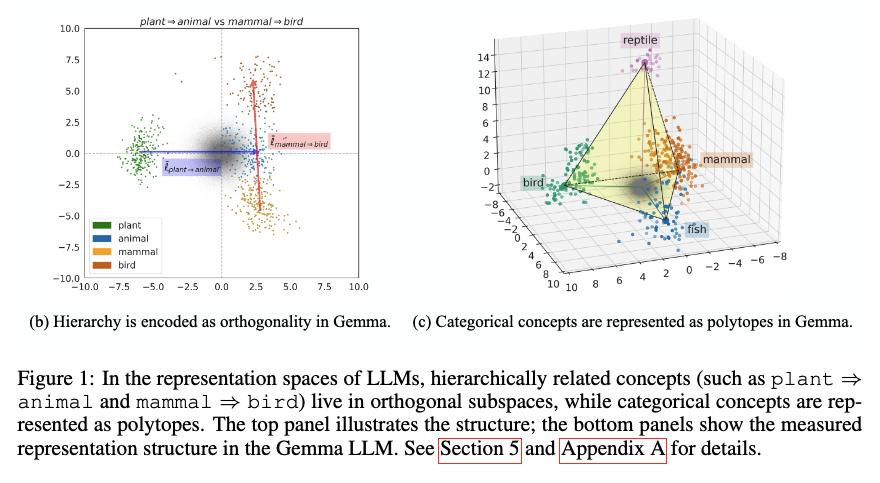
図1. Park ら (2024) Fig 1(Gemma での測定結果)。 (b) 階層関係は直交性として現れる(plant → animal 軸と mammal → bird 軸の散布図)。 (c) カテゴリ概念は polytope として現れる(mammal, bird, reptile, fish の値ベクトルが simplex 状の頂点を作る)。 出典: Park, K., Choe, Y. J., Jiang, Y., & Veitch, V. (2024). The Geometry of Categorical and Hierarchical Concepts in Large Language Models. ICLR 2025.
論文ではこの主張を、3 種類の実験で検証しています。
- 実験 1: 二値特徴評価 — train トークンで推定した「カテゴリ方向」が、未学習の test トークンでも揃い、無関係な random トークンとは分離する、という形で「カテゴリ方向が確かに存在する」ことを確かめる。
- 実験 2: 最短経路 × cosine ヒートマップ — WordNet 上の最短距離と node 同士の cosine の対応をヒートマップで見渡し、階層構造と表現幾何が相関していることを示す。
- 実験 3: 階層直交性の cosine — 親方向と「親 → 子の差分方向」の cosine を計算し、階層直交性そのものを定量的に測る。Park は「高次元では無関係なベクトル同士でも cosine が 0 に近づく」自明性を意識した上で、3 種類の対照(後述)を用意して切り分けを試みる。
本再現実験ではどうなったか
設定
実験には 4 つのモデルを使いました。
| model key | Hugging Face model | 位置付け |
|---|---|---|
gemma2b |
google/gemma-2b |
Park/Golechha との対応が強い英語モデル |
llama3_8b |
meta-llama/Meta-Llama-3-8B |
Park Appendix F との対応 |
qwen35_2b |
Qwen/Qwen3.5-2B-Base |
別系列モデルでの確認 |
llmjp4_8b |
llm-jp/llm-jp-4-8b-base |
日本語への拡張 |
WordNet の lemma をモデルの語彙にどう対応づけるかは tokenizer ごとに違います。Gemma と LLaMA は Park 公式の tokenizer-specific WordNet mapping をそのまま使い、Qwen には Gemma の token strings を Qwen tokenizer で再 filter したものを使いました。LLM-jp については、Open Multilingual WordNet の日本語 lemma を割り当てた Japanese WordNet mapping を本実験で独自に作成しています。
実験 1: 二値特徴評価
各 WordNet node w について、属する token を train / test に分け、train で推定した カテゴリ方向 ℓ̄_w に対して各 token の射影 (projection) を計算します。Park の理論予測は明快で——y がそのカテゴリに属するなら projection は 1 に近く、属さないなら 0 に近くなる、というものです。
本実験で得られた図は次のとおりです。各図とも、左パネルが original unembedding(学習済みのまま)、右パネルが シャッフル後の unembedding(unembedding 行列を行ごとシャッフルした対照)。各色の意味は train (緑)、test (青)、random (橙)、太線が平均、エラーバーが標準偏差です。
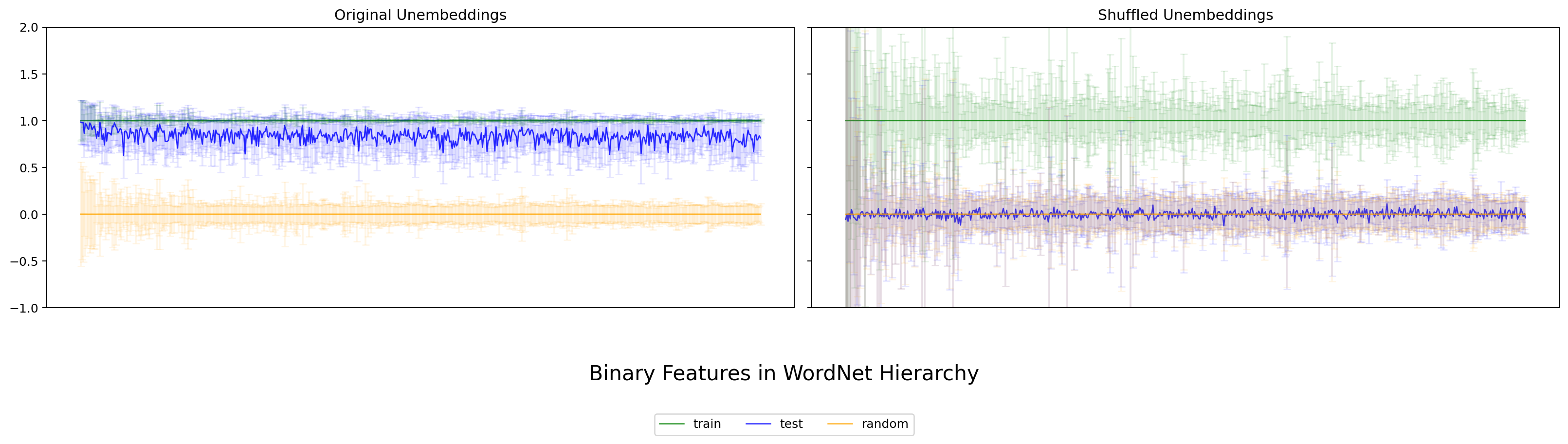
図2. Gemma-2B WordNet の 二値特徴評価 (binary feature evaluation)。 出典: 本再現実験。
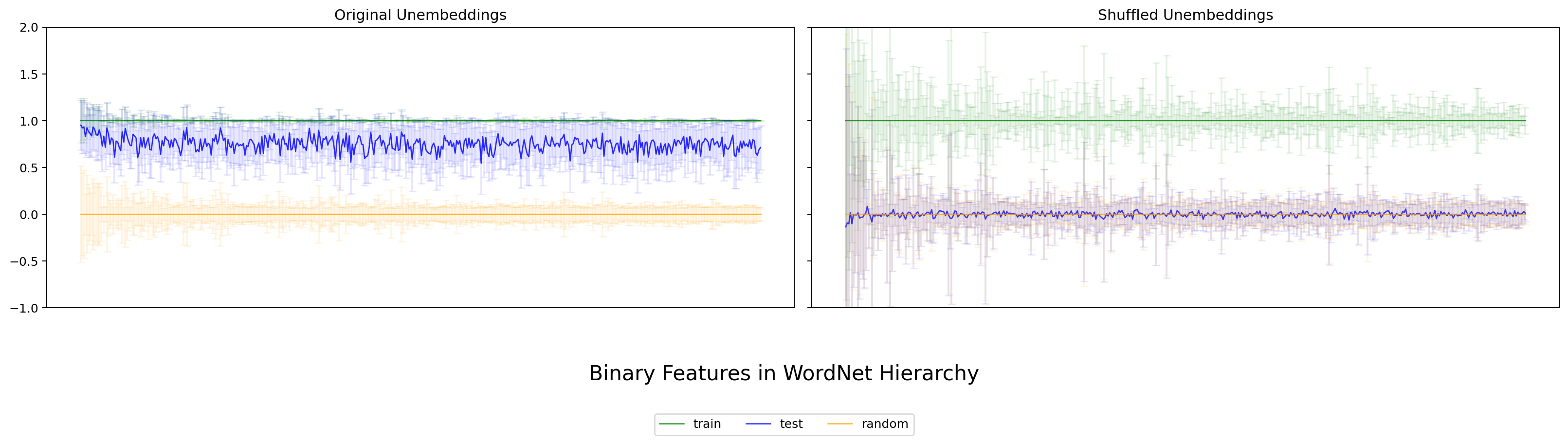
図3. LLaMA-3-8B WordNet の 二値特徴評価。 出典: 本再現実験。
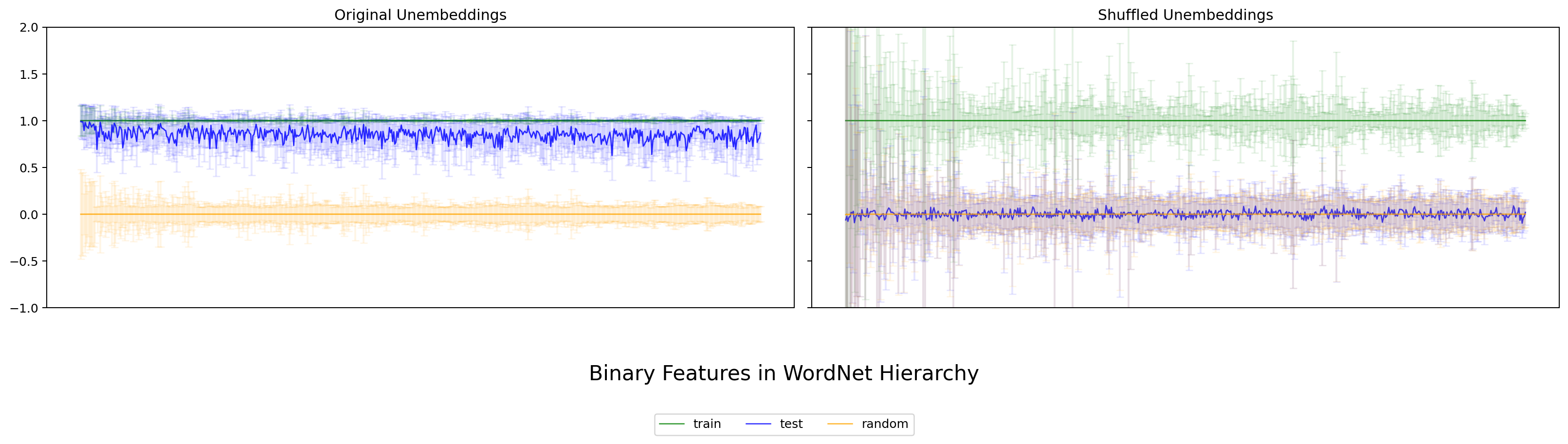
図4. Qwen3.5-2B WordNet の 二値特徴評価。 出典: 本再現実験。
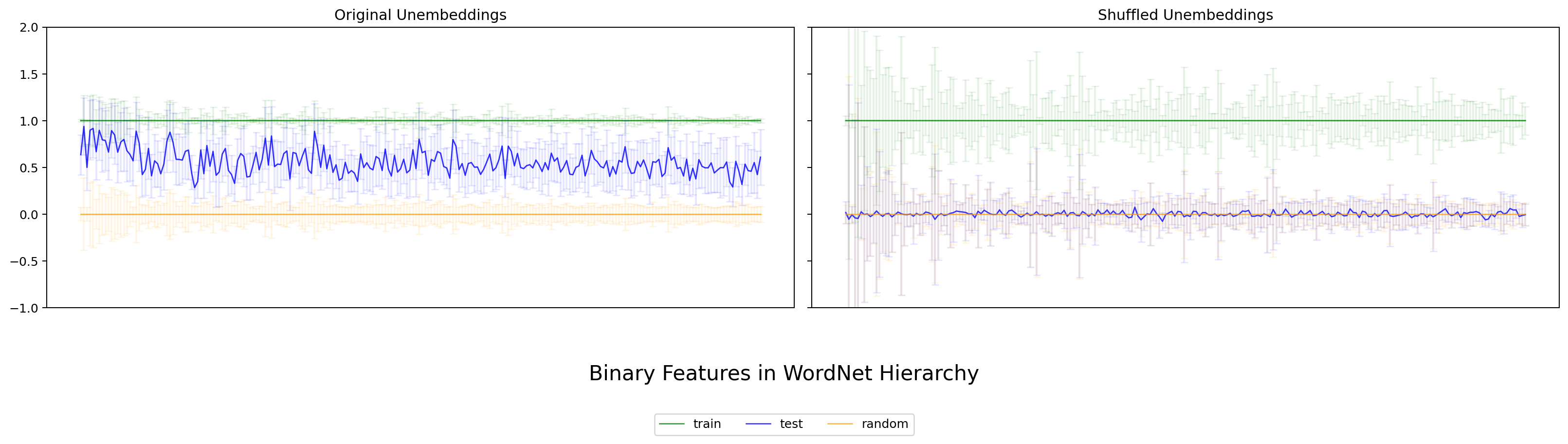
図5. LLM-jp Japanese WordNet の 二値特徴評価(本実験で独自に作成した日本語 WordNet mapping を使用)。 出典: 本再現実験。
4 モデルすべてで、original では train (緑) と test (青) が共に 1 近傍に重なり、random (橙) が 0 近傍に落ちる——という Park の観察が再現できました。Gemma / LLaMA / Qwen の英語モデルだけでなく、日本語の LLM-jp でも同じ傾向が見られる点は、Park の主張が言語に大きく依存しないことを示唆します。一方、シャッフル後では train/test/random いずれも 0 近傍に潰れた一様な分布になり、カテゴリ方向としての意味を失います。
実験 2: 最短経路類似度と cosine ヒートマップ
WordNet 上の各 node ペアについて、最短経路距離に基づく類似度と、ベクトル ℓ̄_w 同士の cosine 類似度を計算し、ヒートマップとして並べて見渡します。Park の理論予測は「中央(cosine original)が左(最短距離)に類似する」というもの。
本実験での 4 モデルのヒートマップを以下に示します。各図の左が WordNet 最短距離 (1+dist)⁻¹、中央が cosine(original)、右が cosine(シャッフル後)です。
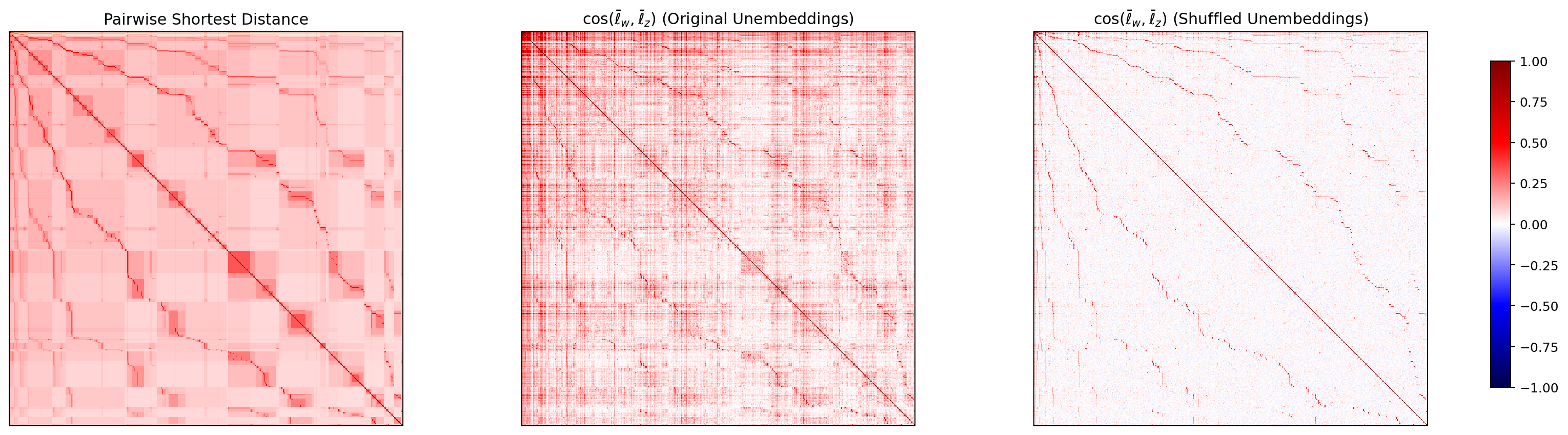
図6. Gemma-2B WordNet の 最短経路類似度と node 方向 cosine ヒートマップ (heatmap)。 出典: 本再現実験。
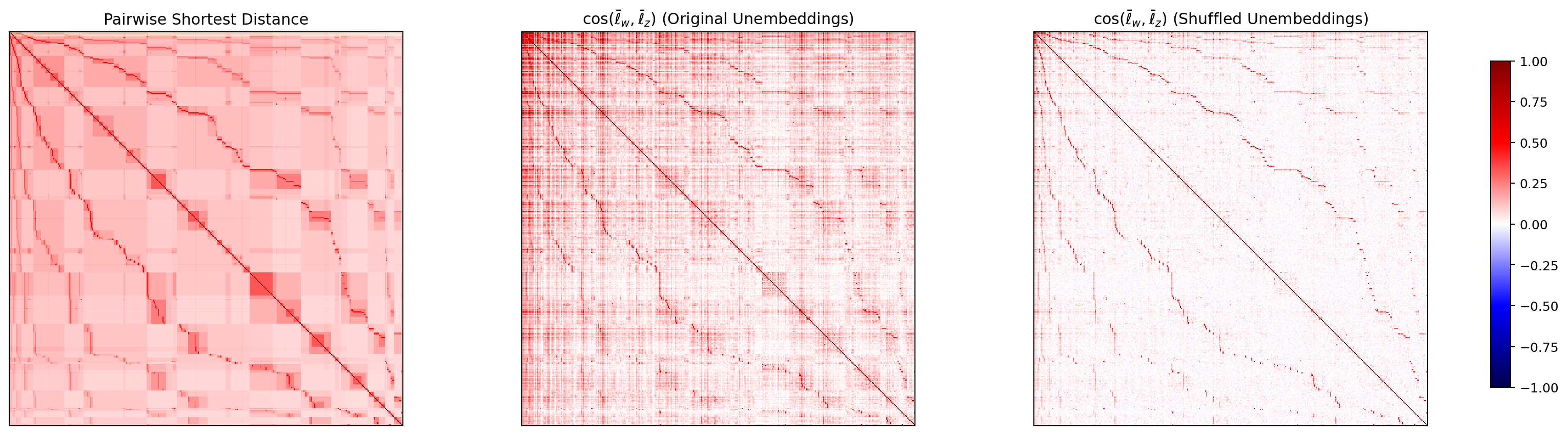
図7. LLaMA-3-8B WordNet の 最短経路類似度と node 方向 cosine ヒートマップ。 出典: 本再現実験。
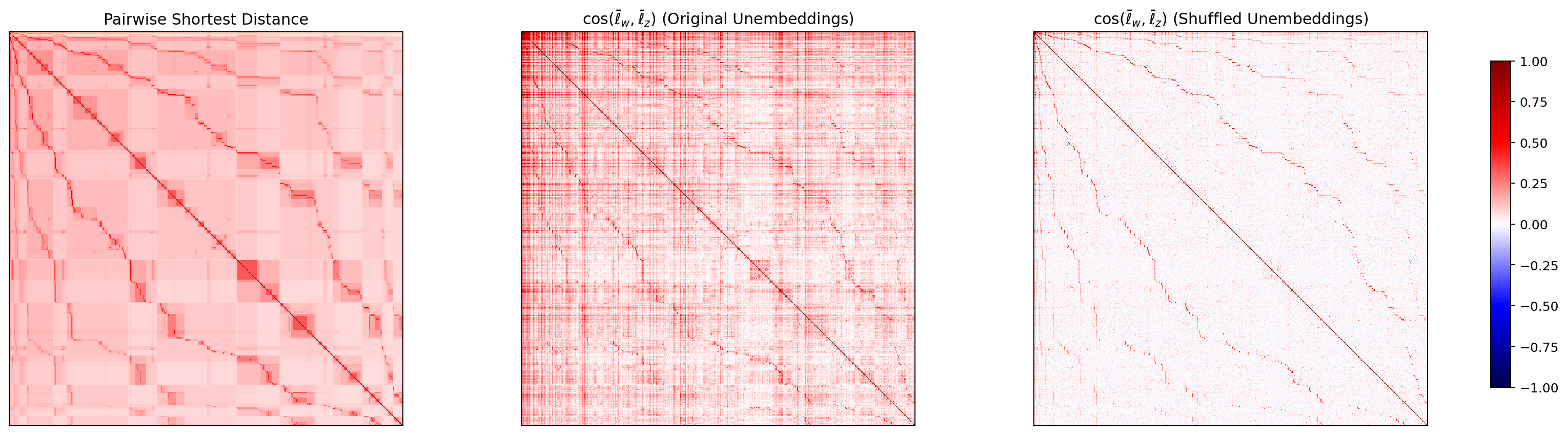
図8. Qwen3.5-2B WordNet の 最短経路類似度と node 方向 cosine ヒートマップ。 出典: 本再現実験。
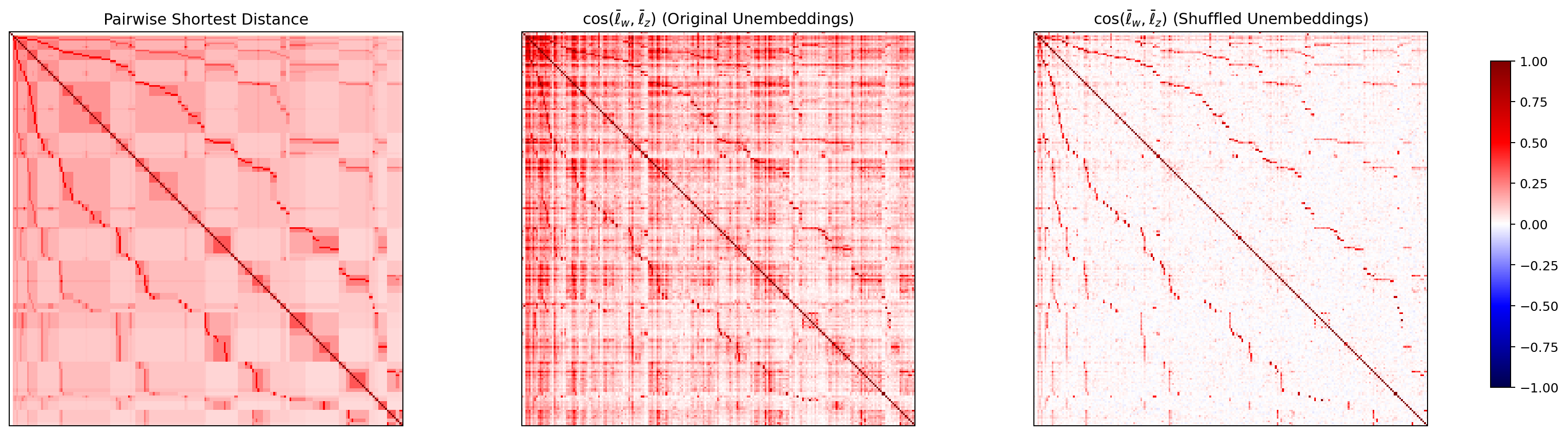
図9. LLM-jp Japanese WordNet の 最短経路類似度と node 方向 cosine ヒートマップ。 出典: 本再現実験。
4 モデルすべてで、左(最短距離)と中央(cosine original)に共通したブロック構造が見え、右(シャッフル後)では模様が消えています。Park の主張する「階層構造と方向構造の対応」が、英語・日本語の双方のモデルで確認できた、と読めます。
実験 3: 階層直交性の cosine
本章の中心指標です。各 WordNet node について、親方向と「親 → 子への差分方向」の cosine(Thm 8(a))を計算し、全 binary feature について並べてプロットします。値が 0 に近いほど Park の主張する 階層直交性 が成り立っていることを意味します。
Park は重要なポイントを意識しています——「高次元空間ではランダムなベクトル同士でも cosine が 0 に近くなりやすい」(Golechha も後にこの点を理論的に詳しく論じます)。そのため、観察された near-zero cosine が高次元の自明な帰結なのか、それとも意味構造に固有の性質なのかを切り分けるために、Park は 3 種類のコントロール を用意しています。
- Random Parent: 親概念を無関係な synset に置き換える。
- シャッフル後の unembedding: unembedding を行ごとシャッフル。
- 70% 独立サブサンプル: 各 synset で独立に 70% のトークンを選ぶことで、集合包含関係を意図的に壊す。決定打のコントロール に位置付けられます。
まず hier_ortho_b(親と子の差分方向の cosine)の結果を 4 モデル分掲載します。各図は左パネルが Whole set、右パネルが Training set(Park Fig 5 の 70% サブサンプルに対応)です。横軸が WordNet 階層上の binary features、縦軸が cosine、青が original、緑がシャッフル後、オレンジが Random Parent。
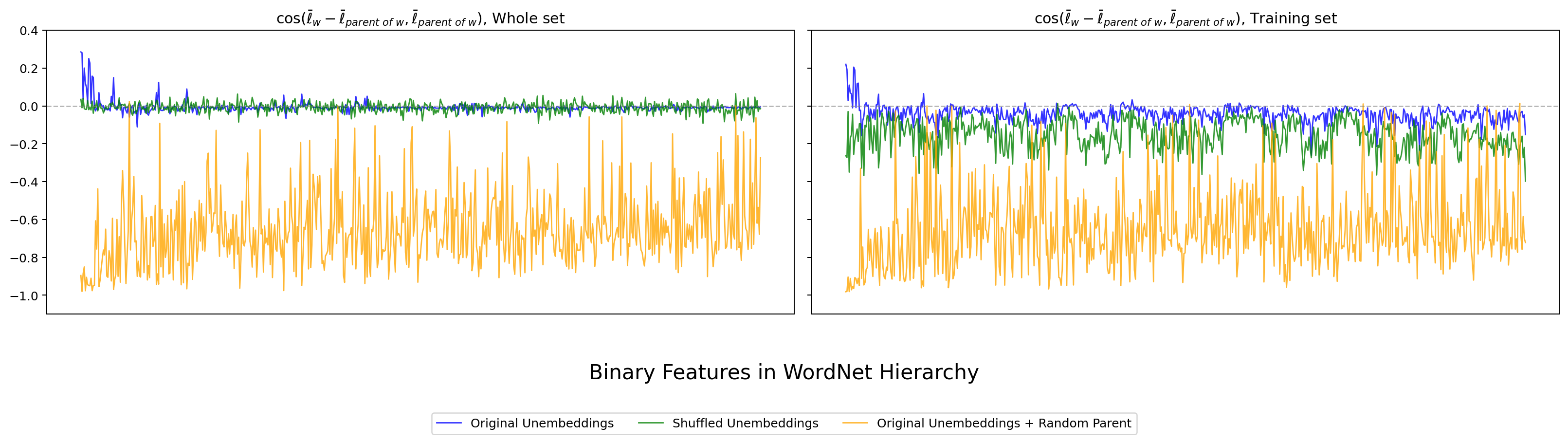
図10. Gemma-2B WordNet の Park-compatible hier_ortho_b。 青が original、緑がシャッフル後、オレンジが Random Parent。 出典: 本再現実験。
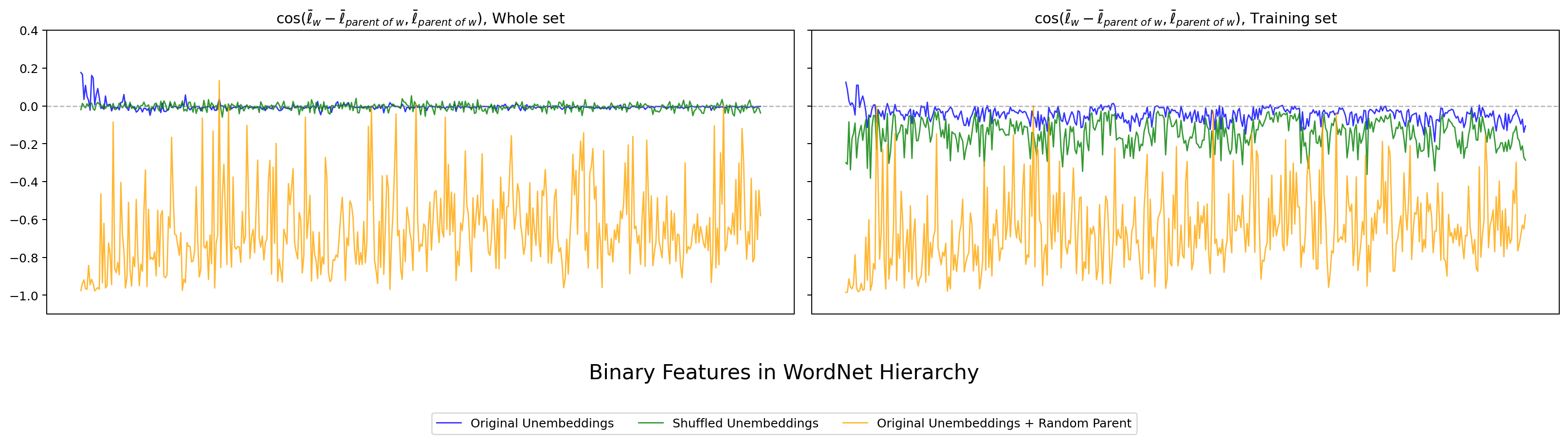
図11. LLaMA-3-8B WordNet の hier_ortho_b。 出典: 本再現実験。
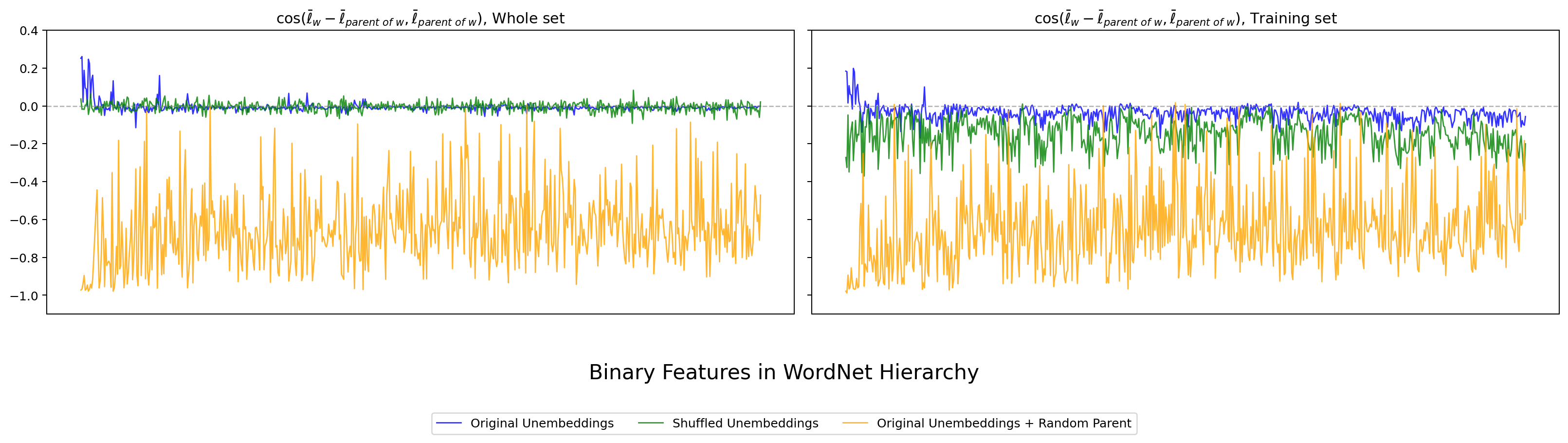
図12. Qwen3.5-2B WordNet の hier_ortho_b。 出典: 本再現実験。
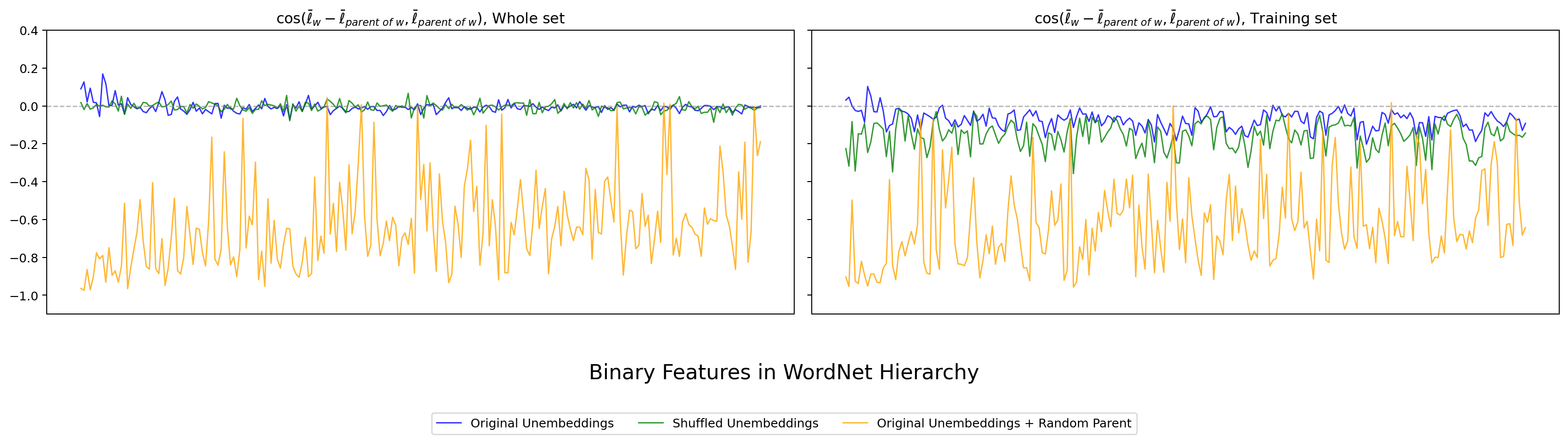
図13. LLM-jp Japanese WordNet の hier_ortho_b。 出典: 本再現実験。
4 モデルすべてで、original (青) の cosine が 0 周辺に集中し、Random Parent (橙) は大きく負に振れるという Park 観察が再現できました。日本語の LLM-jp でも同じ形で現れます。Whole set パネルと Training set パネルで傾向がほぼ同じ点も、Park の Fig 5 と整合的です。
一方、シャッフル後 (緑) は左パネル(Whole set)では original と区別しにくいほど 0 近傍に張り付いており、Park 自身が認めていた「シャッフル後でも 0 近傍は出てしまう」という注意点がそのまま観察できます。これだけでは Park 主張の決定打にならない、という第 4 章への伏線にもなります。
次は hier_ortho_e で、親・子だけでなく祖父概念 (grandparent) まで含めた cosine を見ます。
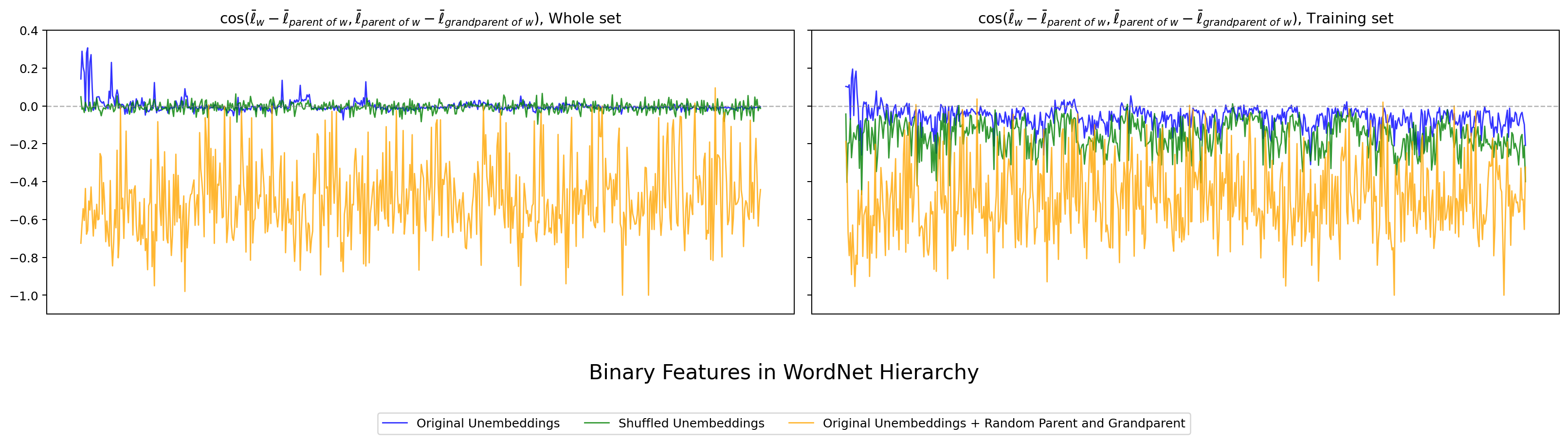
図14. Gemma-2B WordNet の hier_ortho_e(祖父概念まで含めた拡張版)。 出典: 本再現実験。
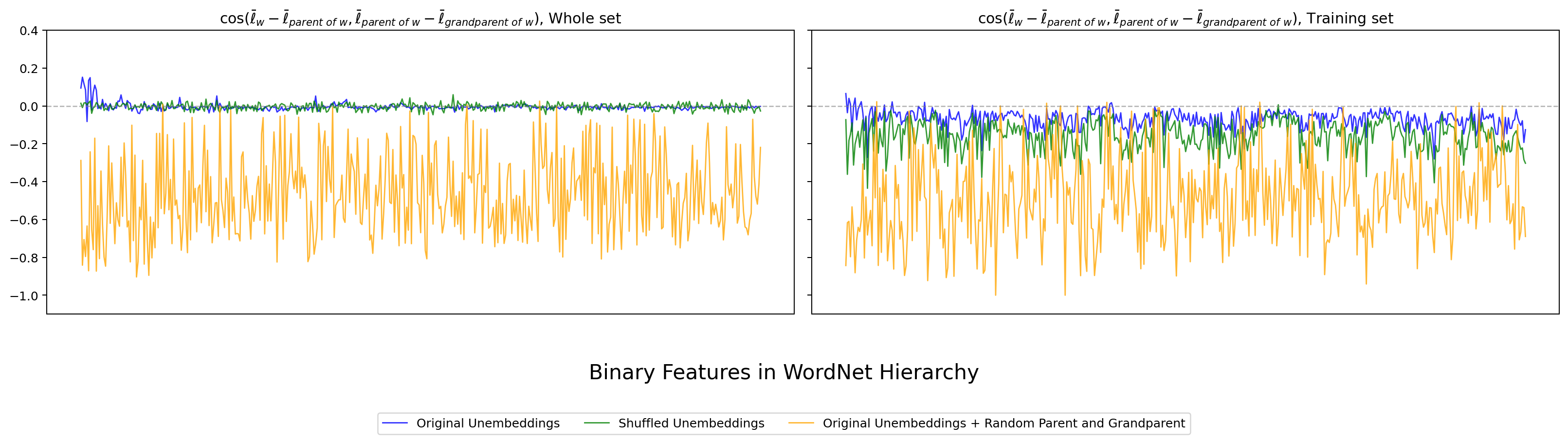
図15. LLaMA-3-8B WordNet の hier_ortho_e。 出典: 本再現実験。
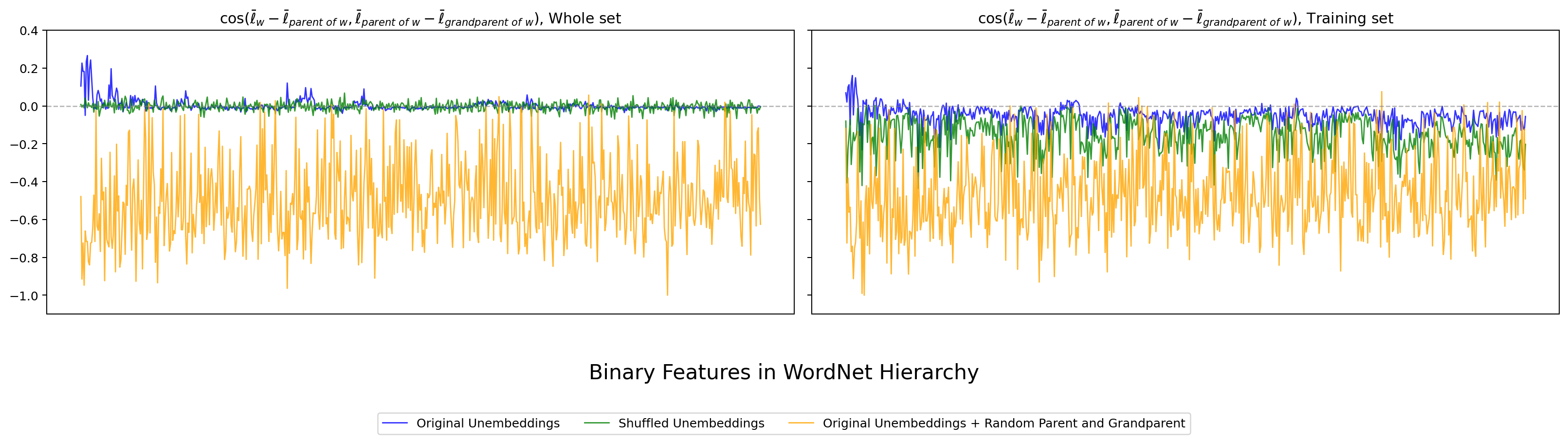
図16. Qwen3.5-2B WordNet の hier_ortho_e。 出典: 本再現実験。
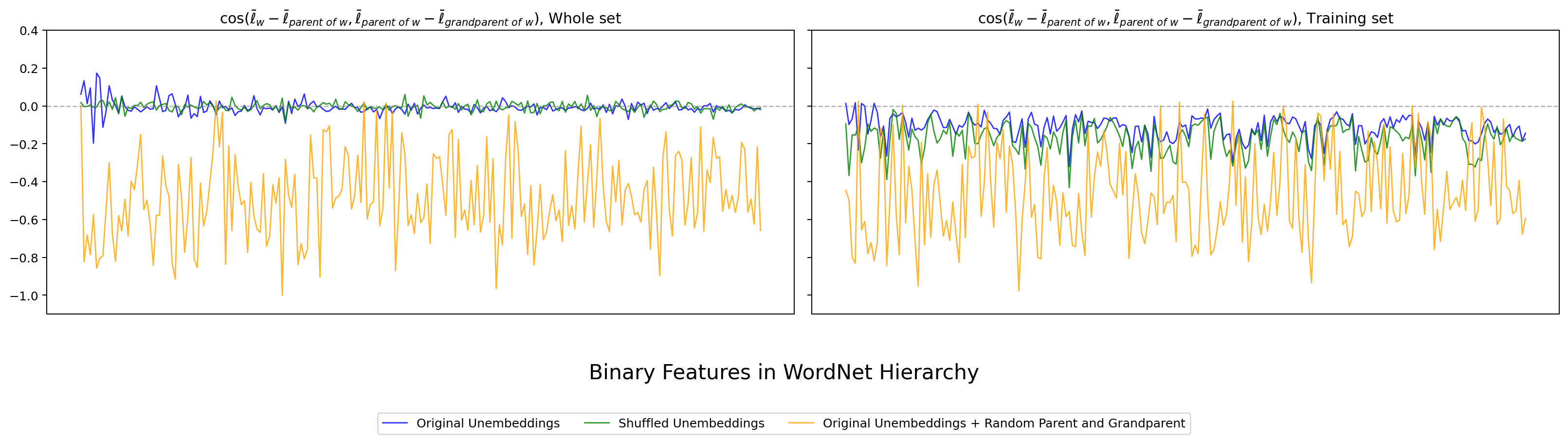
図17. LLM-jp Japanese WordNet の hier_ortho_e。 出典: 本再現実験。
hier_ortho_b と同じ傾向が、孫概念まで広げた場合でも維持されています。二段ぶんの階層直交性も、4 モデル全てで安定に観察できる、と言えます。
考察
図と数値の両方を見るかぎり、Park が注目した WordNet node-level の幾何は、今回の 4 モデルでもかなり一貫して観察できました。日本語 WordNet × LLM-jp という新しい組み合わせでも同じ傾向が再現された点は、本実験の小さな貢献として記録しておきたいところです。
ただ、ここでひとつ立ち止まる必要があります。高次元空間では互いに無関係なベクトル同士でも cosine が 0 に近づきやすい——という、よく知られた性質があるからです。「0 に近い」という事実だけで「意味階層が表現されている」と結論するのは、論理的にやや踏み込みすぎになります。この点こそが、次に紹介する Golechha の問題提起の核心です。
第4章. Golechha ブログと本再現実験
Golechha ブログではこういうことが主張されている
主な主張
Golechha ら (2025) の中心的な主張は、ひとことで言うとこうです。
Park の orthogonality と polytope の結果は、白色化変換と高次元の幾何的性質から来る自明な帰結であって、意味階層に固有の証拠とは言えない。
「Park の図、本当に意味階層を見ているのか?」「意味的にめちゃくちゃなデータでも、同じような図が描けてしまうのではないか?」というのが彼らの問いの核です。
根拠 — 3 つのアブレーション実験
Golechha は Park の公式コードをそのまま使い、入力データだけを差し替えて Park の図を描き直しました。
- Ablation E1 (emotions): 自然な階層を持たない感情カテゴリ(joy, sadness, anger, fear, surprise, disgust)でも、Park 風の polytope 図と near-zero cosine が得られる。Golechha 曰く「joy と sadness は意味的に反対なのに、彼らの変換のもとでは『直交している』ように見えてしまう」。
- Ablation E2 (nonsense): 意味的につながりのないランダムな物体名の集合(toaster, penguin, cactus, ...)でも、同様の見た目になる。
- Ablation E3 (random unembedding): unembedding 行列を学習なしの Gaussian に置き換えても、白色化を通すと near-zero cosine と simplex 的構造が出る。学習されていないランダムな出力層なのに、Park 風の図が描けてしまうわけです。
根拠 — 理論的な議論
Golechha はアブレーションだけでなく、なぜそうなるのかの理論的な議論も合わせて展開しています。要点はカテゴリ token 数 n とモデル次元 d の関係を 2 つの場合に分けて論じたものです。
- d ≥ k の場合: 白色化変換は概念ベクトルを厳密に直交化できる。「適当に作った概念階層」でも Theorem 8 の式が成立してしまう。
- d < k の場合: 高次元空間ではランダムベクトル間の cosine が「平均 0、ばらつき ≈ 1/√d」に集中する測度集中の性質がある。Gemma-2B なら d = 2048 なので 1/√d ≈ 0.022。「無関係なベクトル同士でも near-zero cosine」が確率的にほぼ常に成立する。
留保事項
ただし注意したい点が二つあります。
ひとつ目は、Golechha 自身が Park の animals における結果そのものは否定していないことです。彼らの主張は「Park の検証方法が意味構造の有無を識別できない (non-diagnostic)」というもので、Park の animals での結果が間違っているとは言っていません。
ふたつ目は、ブログ記事には mean cos や信頼区間、統計検定といった定量指標が提示されていないことです。視覚的に「同じに見える」という主張に留まっています。さらに、Park 論文 §5.2 が提示している 70% 独立サブサンプル診断(前述の B4)を nonsense / random unembedding で実施した結果も、ブログ内には見当たりません。
これらが本実験の独自部分の出発点になります。
本再現実験ではどうなったか
独自性と狙い
- Park の 70% 独立サブサンプル診断を 4 モデル横断で定量化: Park は Gemma-2B 単独で Fig 5 として視覚提示するにとどめていますが、本実験では
B4(サブサンプル単独)とB5(サブサンプル + シャッフル)として 6 種類のアブレーションに組み込み、Golechha の 3 条件と Park の追加診断を同じ枠組みで読み比べられる形にしました。 - 4 モデル × 30 seed の信頼区間つき比較: Park / Golechha どちらも単発実行ですが、本実験では 30 seed の平均と 95% 信頼区間を取り、観察値が偶然か実体かを切り分けられる形にしています。
- 日本語拡張による言語非依存性の確認: LLM-jp と日本語 WordNet を使い、英語以外の言語でも Park 主張がどう見えるかを確かめます。
設定
本実験では、4 モデルに対して animals, emotions, nonsense の 3 つのデータセットを実行しました。さらに Park の主張を多面的に検証するため、6 種類のアブレーションを比較しています。
| 条件 | 内容 | 何を確かめたいか / 期待 |
|---|---|---|
B1 |
original unembedding(無加工) | 基準条件。Park 主張どおりなら cosine は 0 近傍。 |
B2 |
random parent(親概念をランダムに選び替え) | 親をランダム化したら直交性は壊れるはず。「破壊基準」を与える。 |
B3 |
シャッフル後の unembedding | Park 主張どおりなら 0 から外れるが、高次元では壊れない可能性も。 |
B4 |
70% 独立サブサンプル | Park 提案の独立サブサンプル診断。意味階層が因果的に表現されているなら結果は保たれるはず。 |
B5 |
シャッフル + 70% 独立サブサンプル | B4 単独との差から「シャッフルで壊れる構造」が浮かび上がる。 |
C5 |
Gaussian random unembedding | Park 主張どおりなら 0 から外れるはずだが、もし 0 近傍になるなら Golechha の主張を支持。 |
このうち B4 は Park 自身が論文中で言及した独立サブサンプル診断に、B5 はそこにシャッフルを組み合わせたものに対応します。B4 と B5 の差は本実験で初めて系統的に定量化したものです。seed は 0 から 29 まで使い、結果は repro/results/summary.csv に集計しています。
可視化
Golechha ブログの主要な論点は「animals 以外のカテゴリや random unembedding でも Park 風の投影図・polytope 図が見えてしまう」というものでした。本実験でも、これに対応する可視化を生成しています。
ここでは本実験の独自部分である日本語モデル LLM-jp-4-8B × animals データセットで、6 条件すべてを並べます。各条件とも左が 2D projection、右が 3D simplex-polytope です。B1 と C5 を見比べると Golechha の主張がよく分かり、B2〜B5 の比較からは Park の追加診断がどの程度区別できるかが見えてきます。
B1: original unembedding。 無加工の基準条件です。
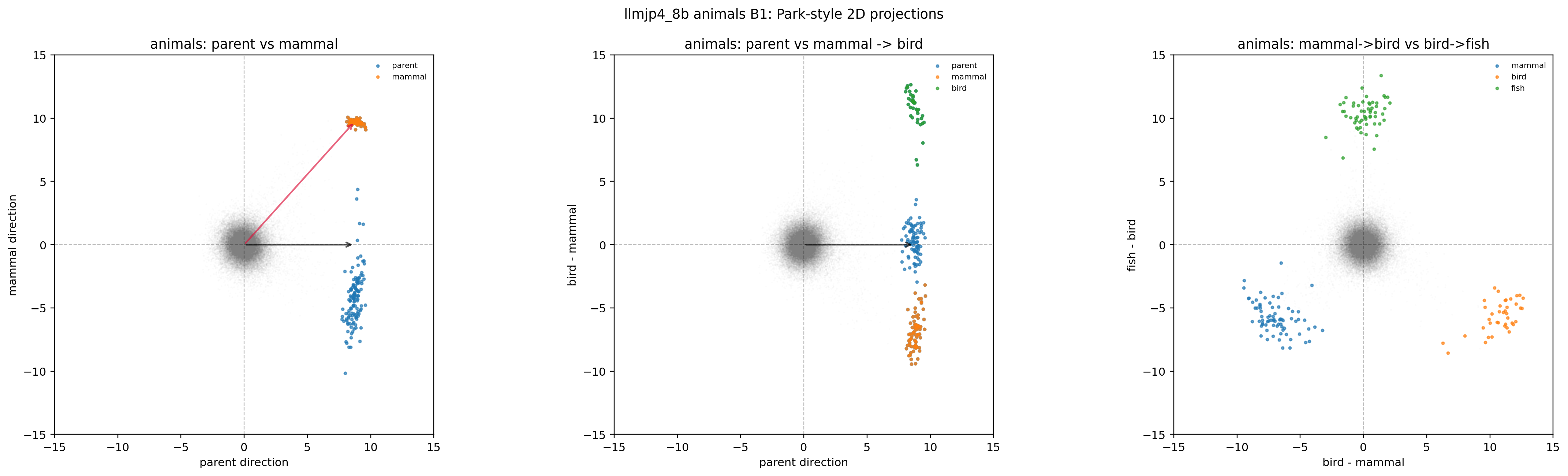
図18. LLM-jp animals × B1(Park-style 2D projection)。 期待どおり、parent 軸(黒矢印)に沿った差分がきれいに現れる。 出典: 本再現実験。
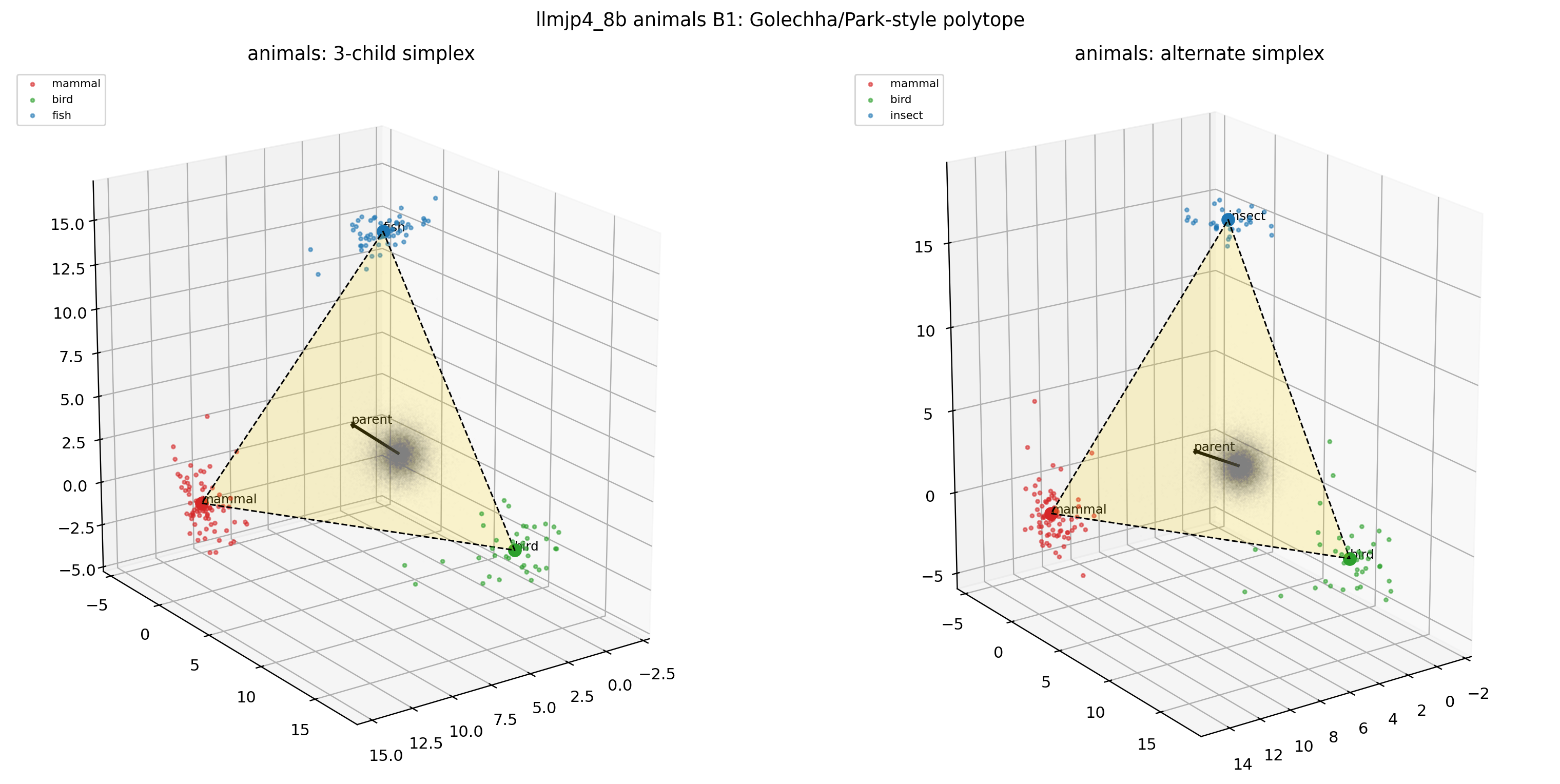
図19. LLM-jp animals × B1(3D simplex-polytope)。 3 つのカテゴリ値ベクトルが simplex 状の頂点を作る。 出典: 本再現実験。
参考までに、emotions と nonsense の B1 も並べておきます。自然な階層がない感情カテゴリでも、無意味なカテゴリでも、見た目は animals と似ています。
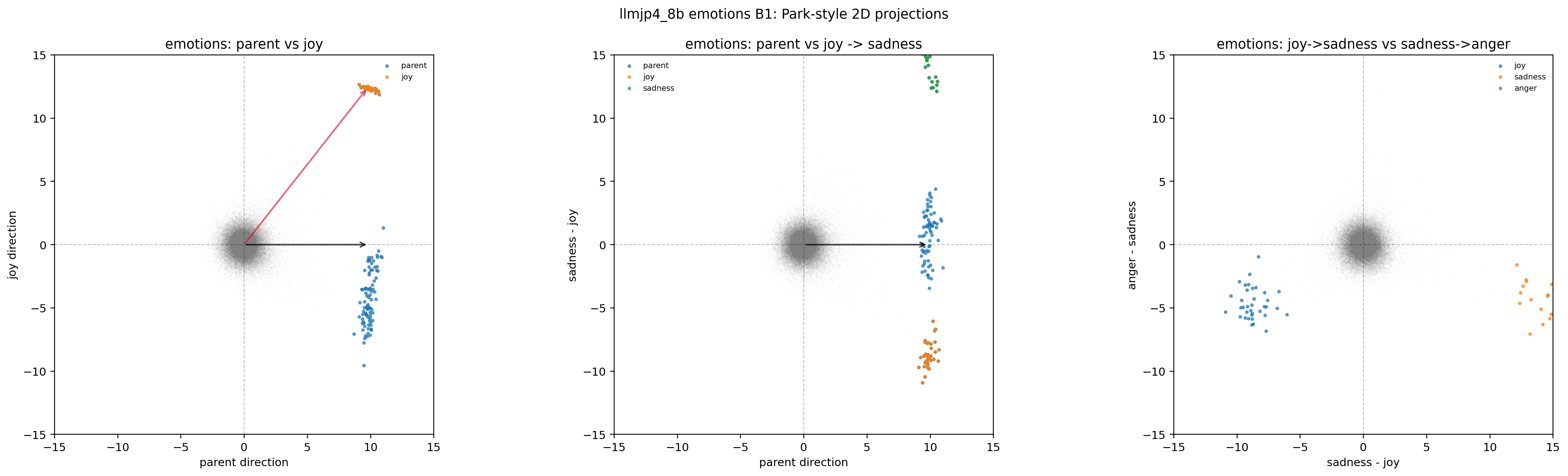
図20. LLM-jp emotions × B1(2D projection)。 自然な階層がない感情カテゴリでも、見た目は animals と似ている。 出典: 本再現実験。
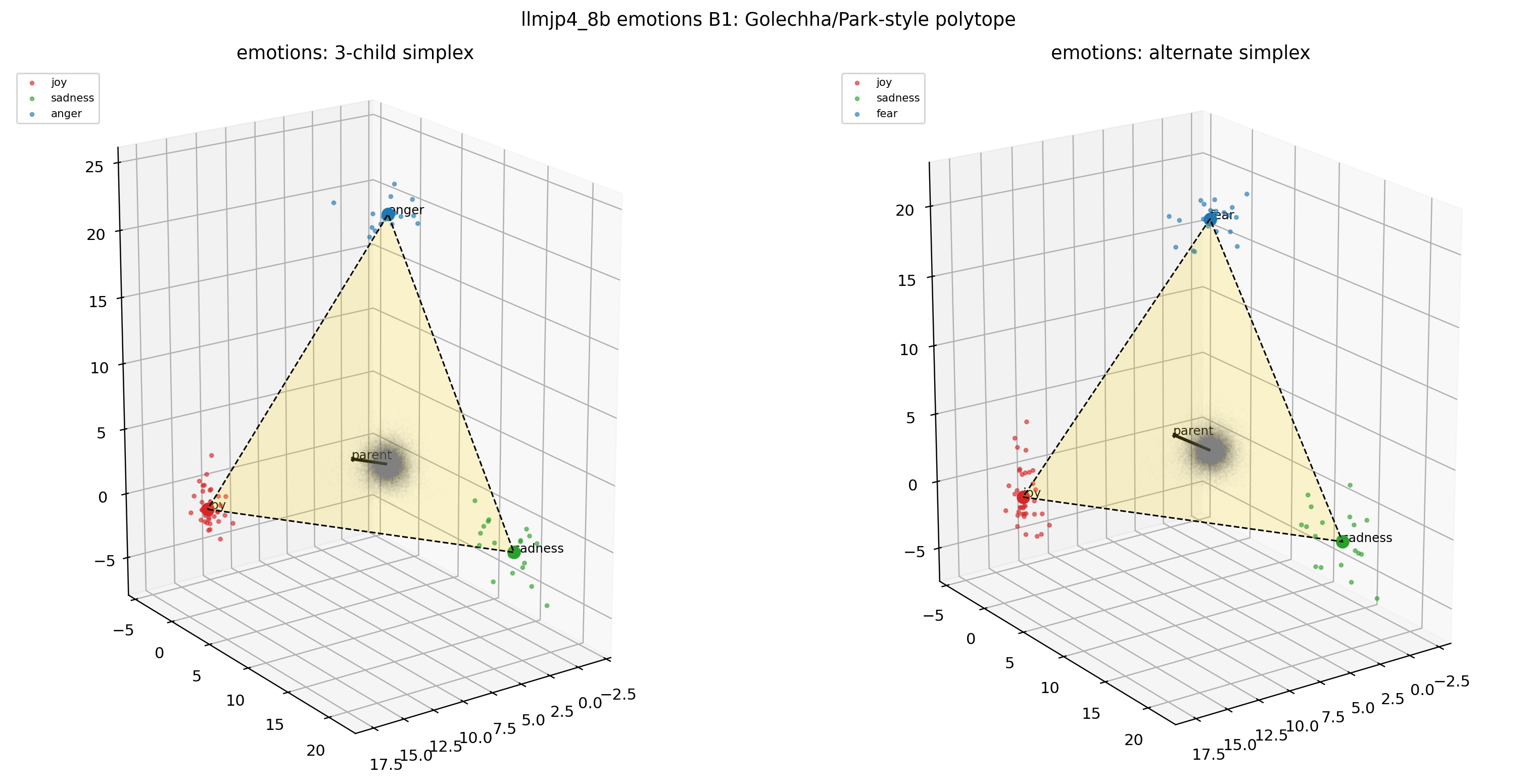
図21. LLM-jp emotions × B1(3D simplex-polytope)。 出典: 本再現実験。
図22. LLM-jp nonsense × B1(2D projection)。 無意味なカテゴリでも形だけは similar に出る。 出典: 本再現実験。
図23. LLM-jp nonsense × B1(3D simplex-polytope)。 出典: 本再現実験。
B2: random parent。 親概念を無関係な synset にすり替えた条件。Park 主張どおりなら polytope は大きく崩れるはずで、これが「壊れた図」の基準を与えます。
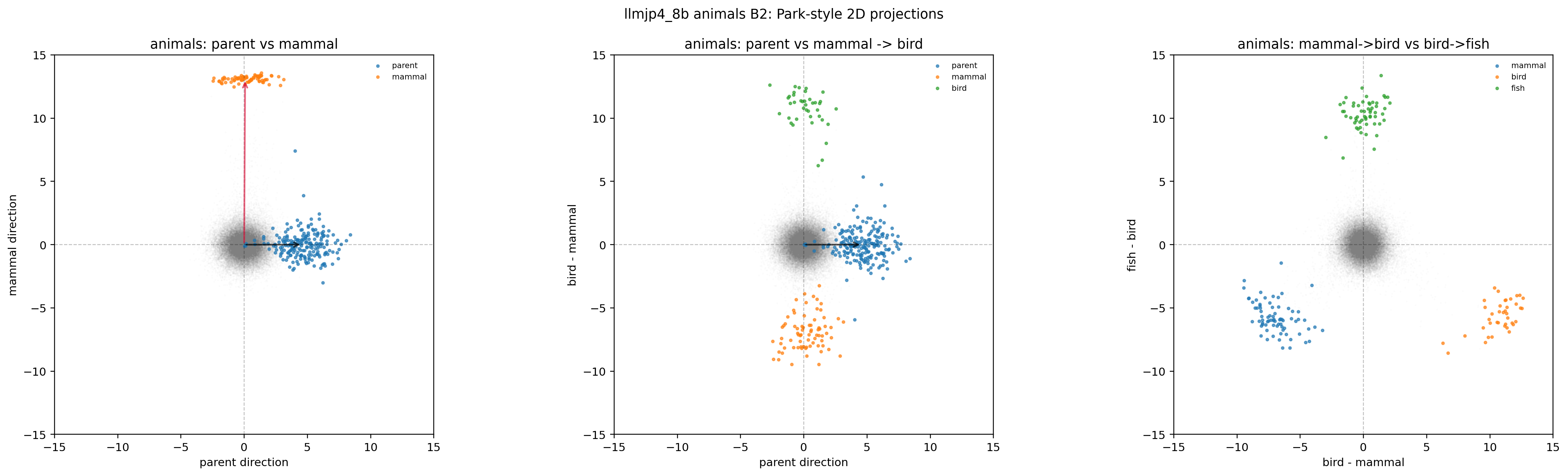
図24. LLM-jp animals × B2(random parent)の 2D projection。 期待どおり parent ベクトルが本来の方向から外れている。 出典: 本再現実験。
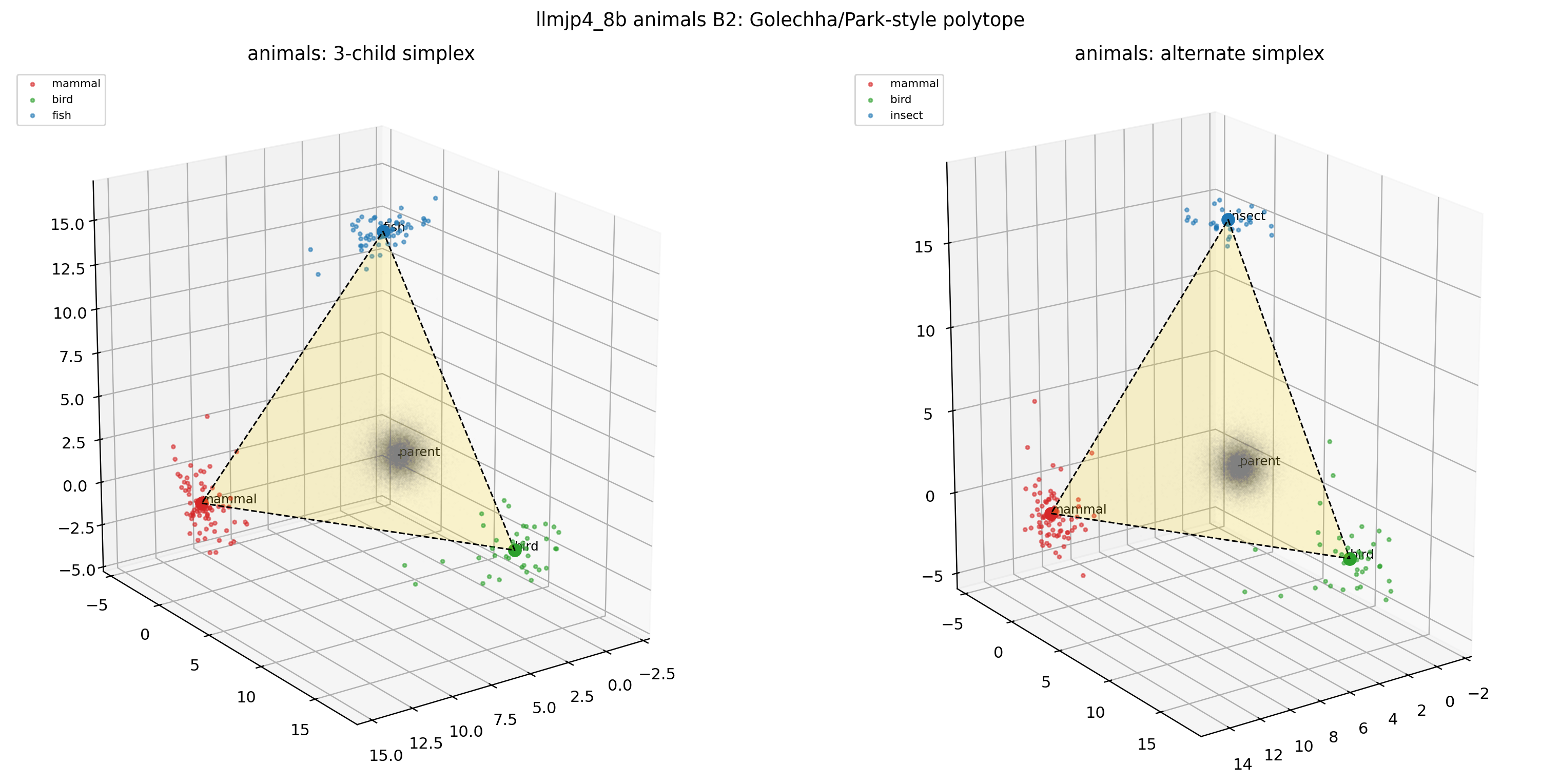
図25. LLM-jp animals × B2(random parent)の 3D polytope。 頂点配置が崩れている。 出典: 本再現実験。
B3: シャッフル後の unembedding。 unembedding 行列を行ごとシャッフル。Golechha の指摘通り、高次元では simplex の形が思ったほど崩れず、B1 と区別しにくいことを確認してください。
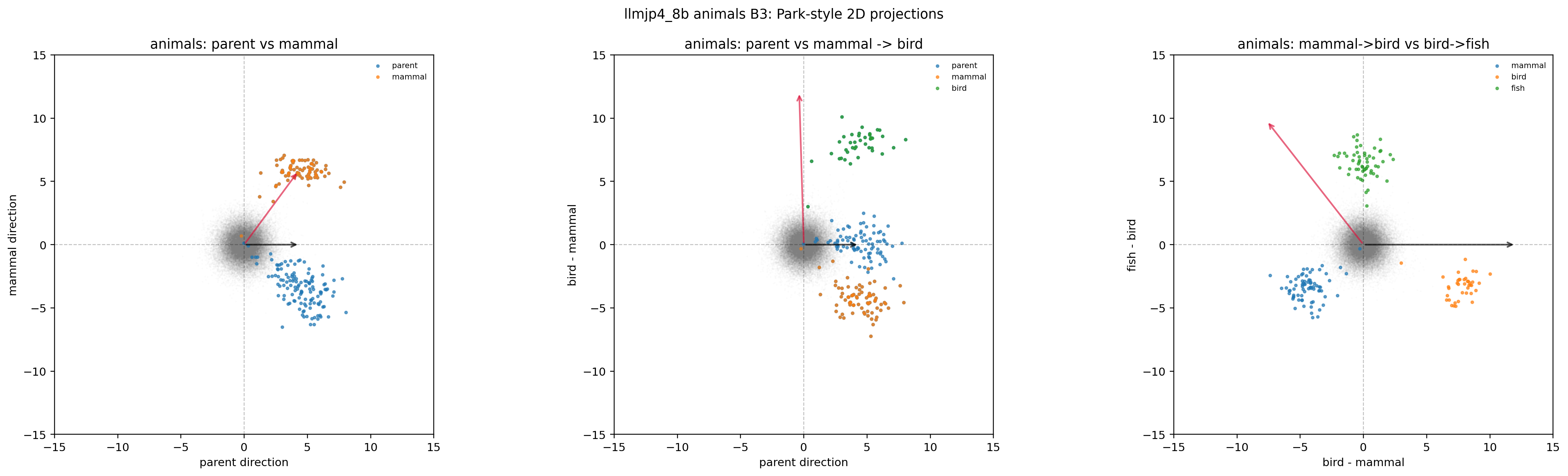
図26. LLM-jp animals × B3(シャッフル後の unembedding)の 2D projection。 出典: 本再現実験。
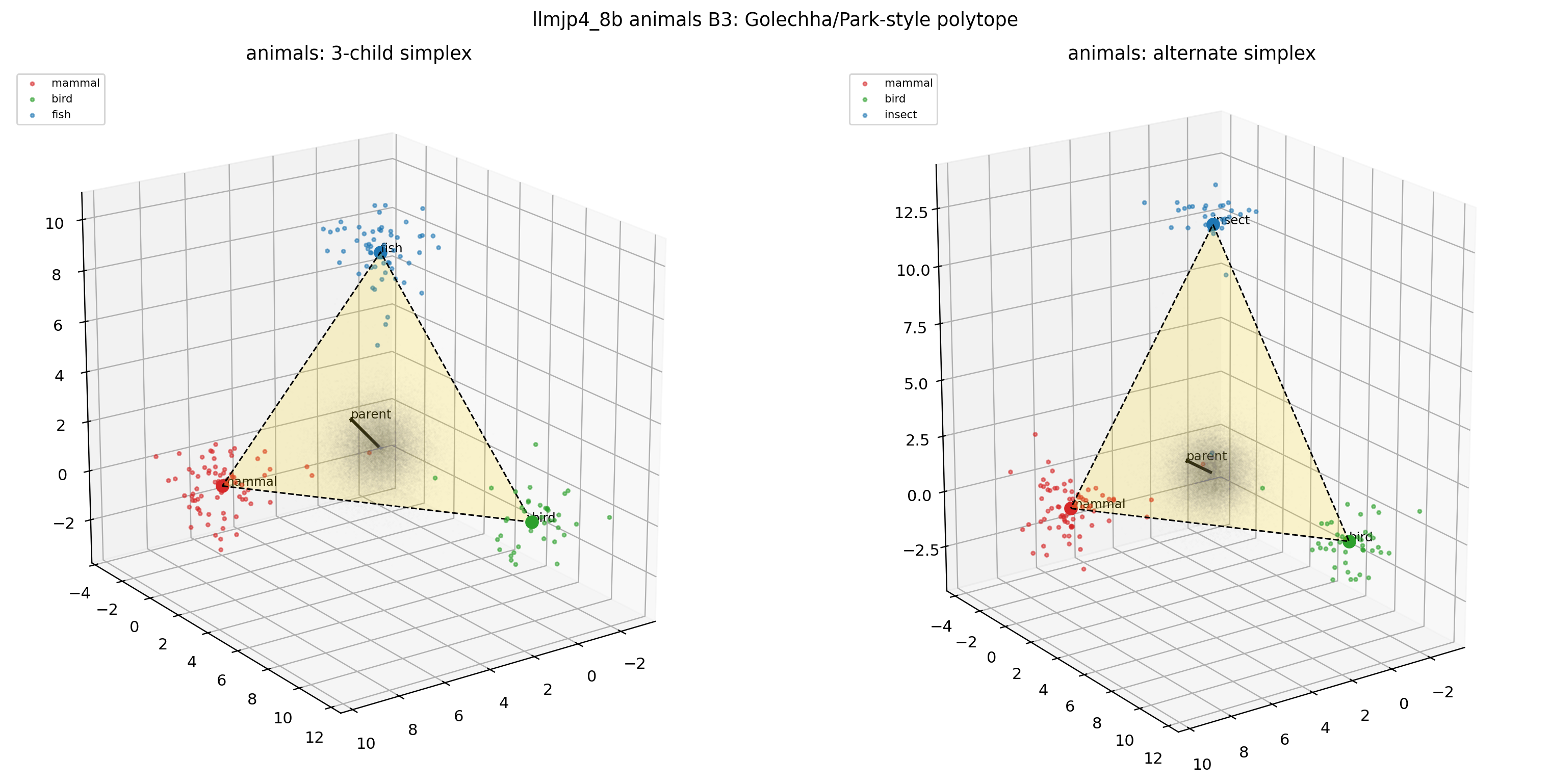
図27. LLM-jp animals × B3(シャッフル後の unembedding)の 3D polytope。 意外にも simplex の形は B1 とそれほど違わない。 出典: 本再現実験。
B4: 70% 独立サブサンプル。 Park の決定打のコントロールに対応します。サブサンプル単独だと polytope が B1 とほぼ同じ程度に維持されます。
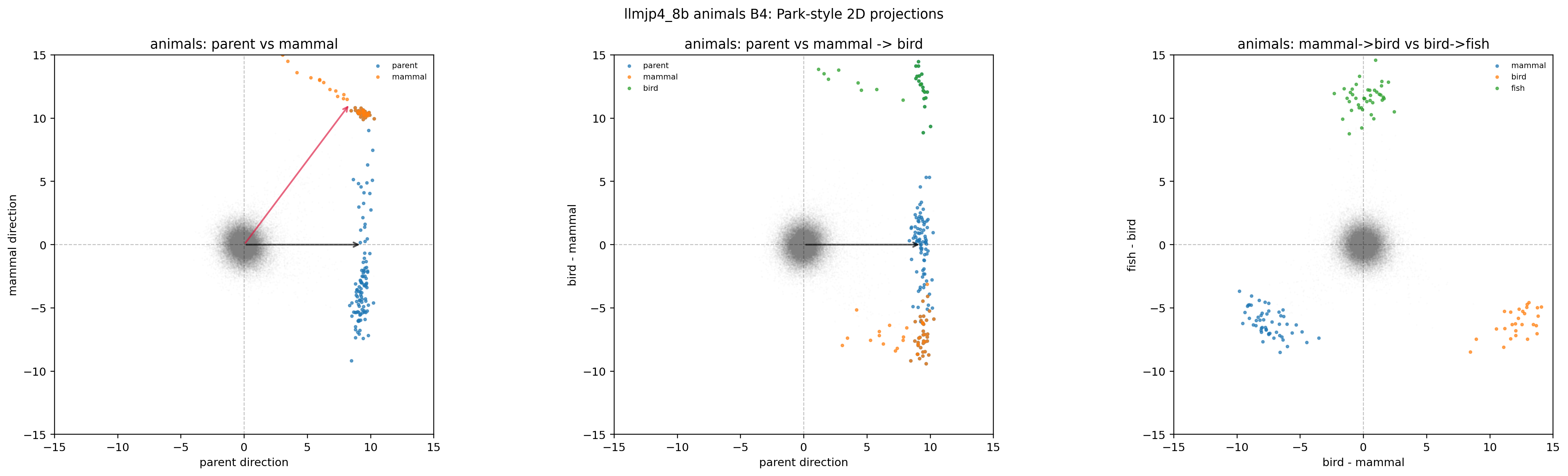
図28. LLM-jp animals × B4(70% 独立サブサンプル)の 2D projection。 出典: 本再現実験。
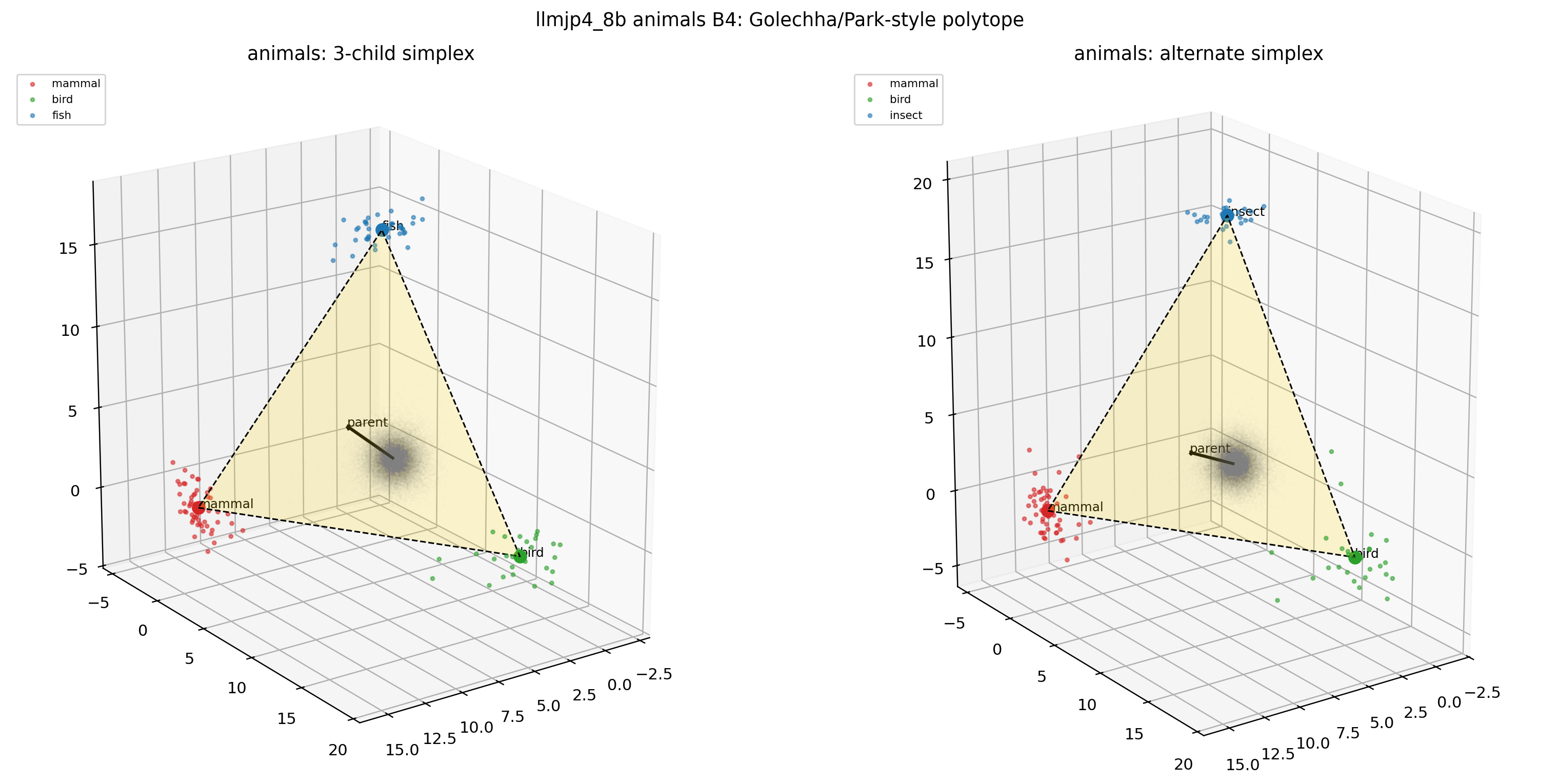
図29. LLM-jp animals × B4(70% 独立サブサンプル)の 3D polytope。 サブサンプル単独だと polytope の形は B1 とよく似たまま保たれる。 出典: 本再現実験。
B5: シャッフル + 70% サブサンプル。 Park の決定打のコントロールの中核です。B4 と比較して polytope の頂点配置が明らかに乱れていることを見比べてください。これが trained unembedding に残る構造の所在です。
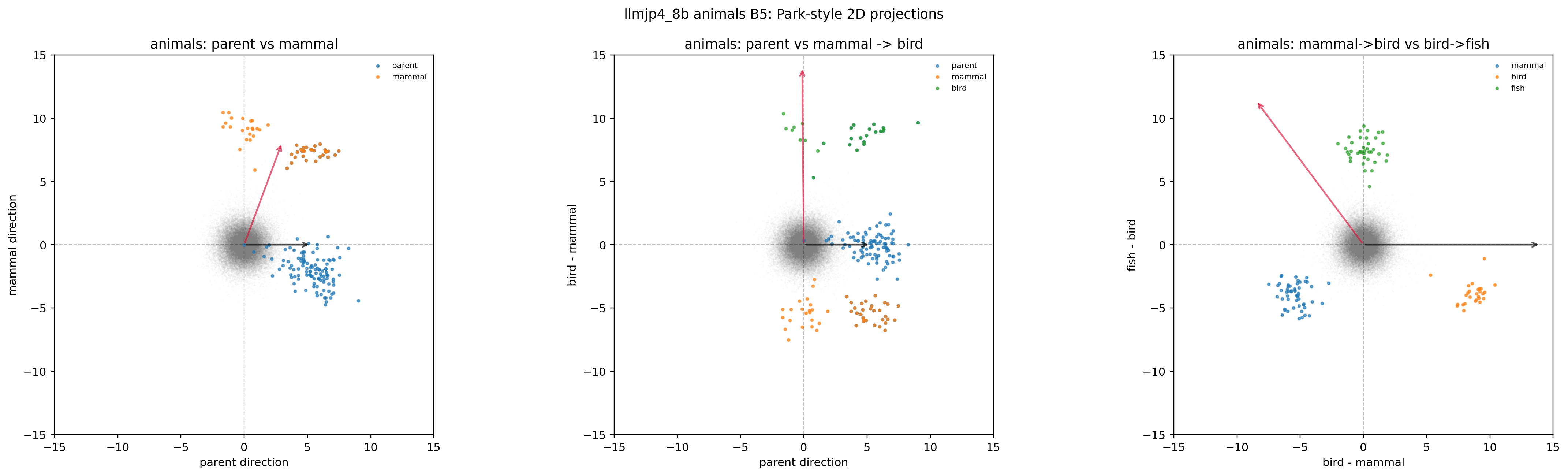
図30. LLM-jp animals × B5(シャッフル + 70% サブサンプル)の 2D projection。 出典: 本再現実験。
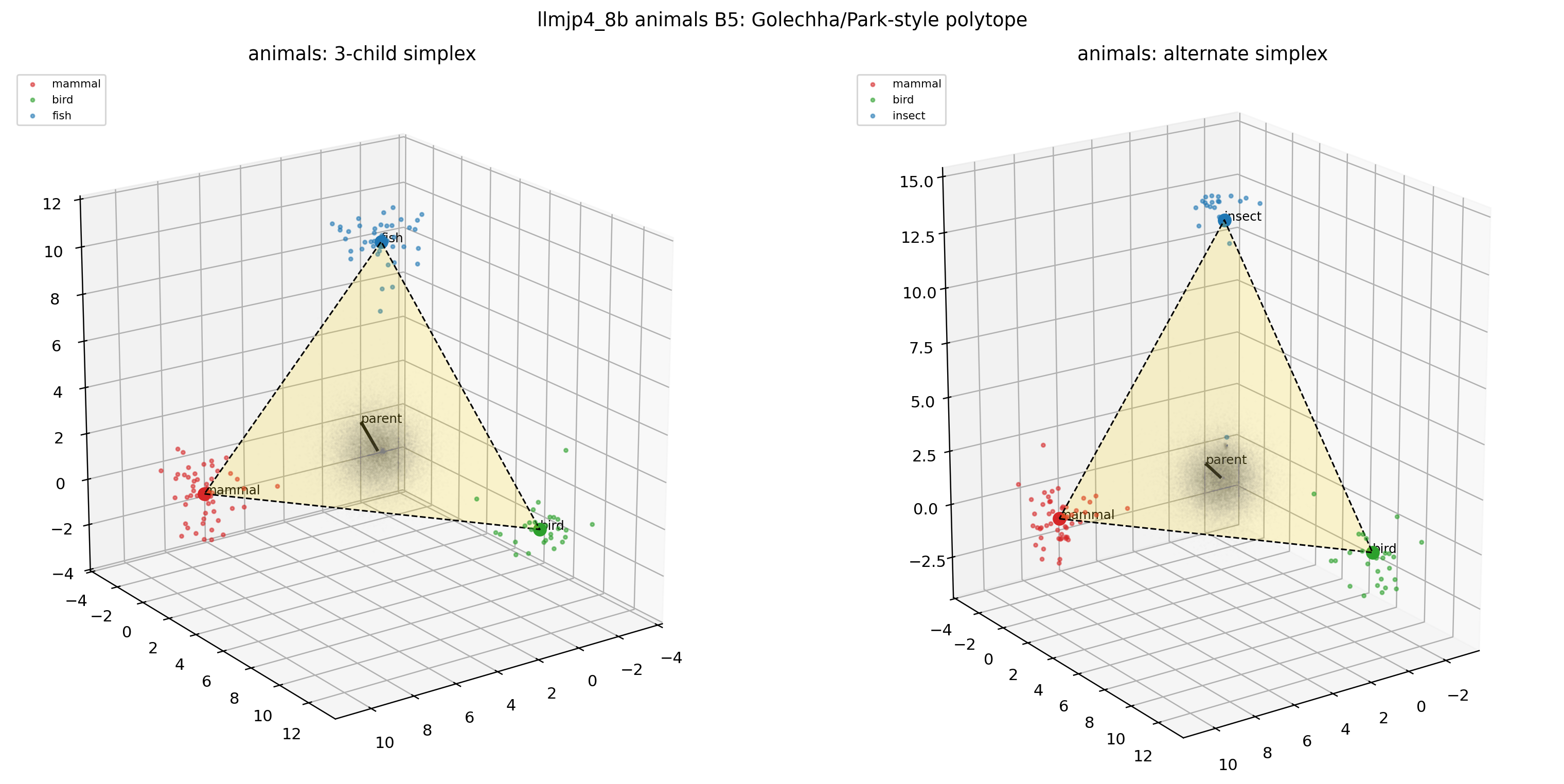
図31. LLM-jp animals × B5 の 3D polytope。 B4 と比べると polytope の頂点配置が大きく崩れる——Park の追加診断が捉える構造の所在。 出典: 本再現実験。
C5: Gaussian random unembedding。 unembedding 行列を学習なしの Gaussian で置き換えた極端な条件。Park 主張どおりなら polytope は全く出ないはずです。しかし図のとおり simplex の形が消えていない(B1 と区別しにくい)ことを確認してください。これが Golechha の批判の決定打にあたる例です。
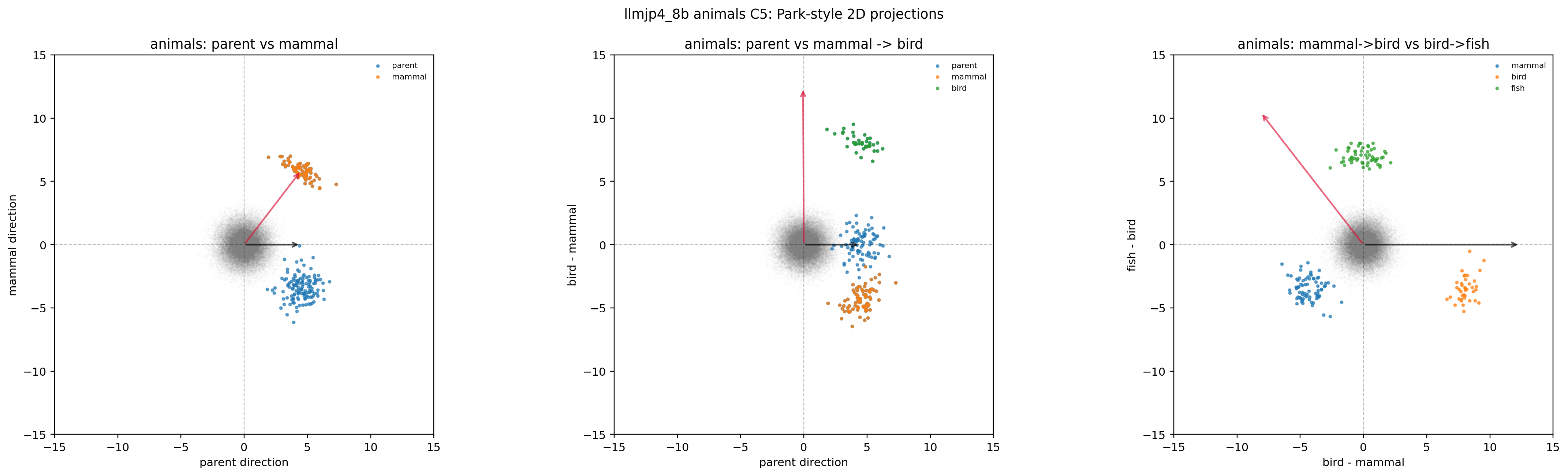
図32. LLM-jp animals × C5(Gaussian random unembedding)の 2D projection。 学習されていないランダムな出力層でも構造らしい形が出てしまう。 出典: 本再現実験。
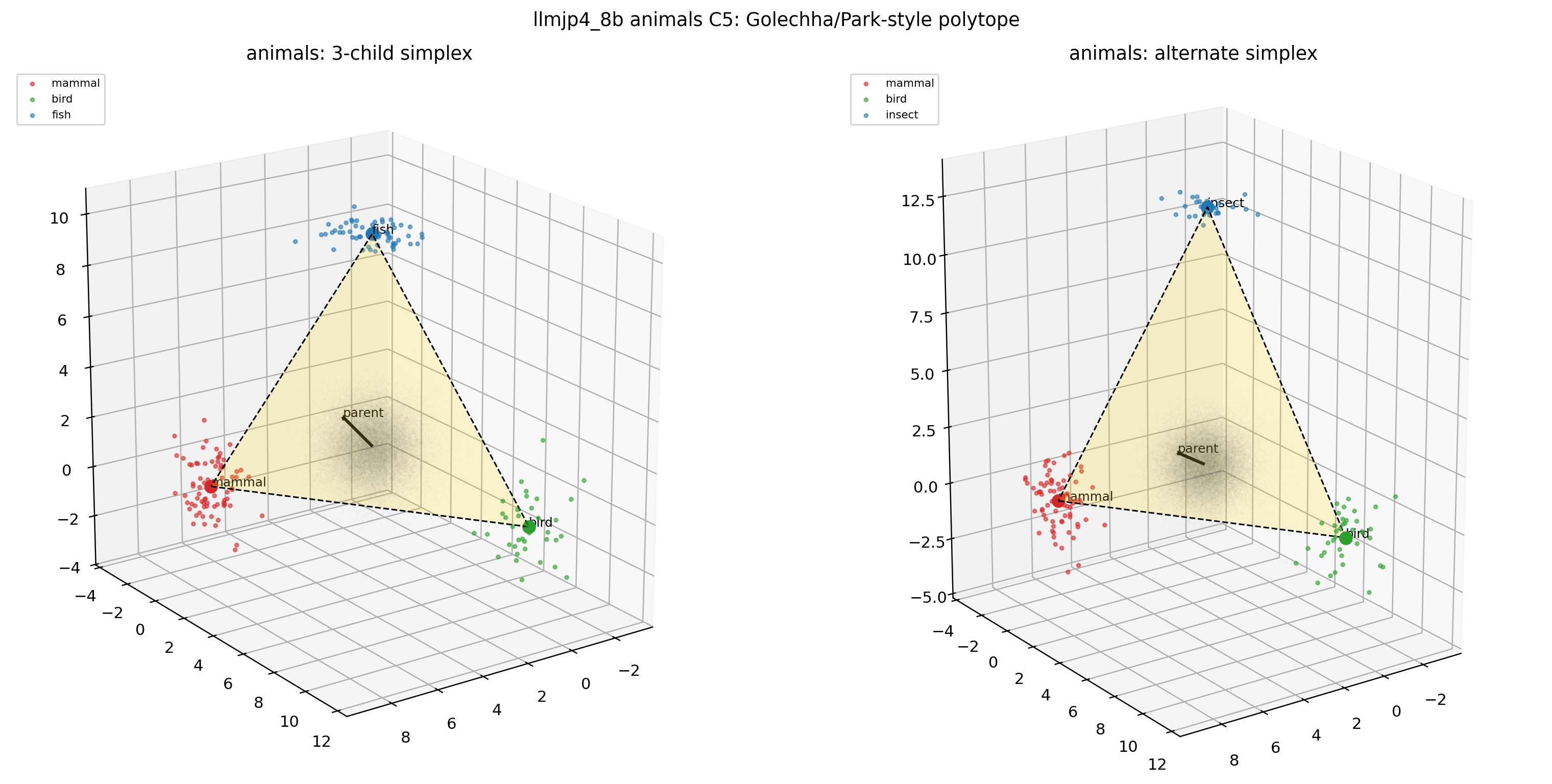
図33. LLM-jp animals × C5 の 3D polytope。 学習されていないランダムな出力層でも simplex-polytope 風の見た目が得られてしまう。 出典: 本再現実験。
これらの図から読み取れるのは、animals だけでなく emotions, nonsense, さらには C5 random unembedding でも、投影図や simplex-polytope 的な見た目がそれなりに得られてしまう、という事実です。「図の見た目だけでは意味階層に固有の証拠とは言いにくい」という Golechha の主張が、日本語モデルでも視覚的に納得できる形になっています。一方で B2 (random parent) や B5 (シャッフル + サブサンプル) では polytope の形が大きく崩れ、Park の追加診断が確かに信号と雑音を区別する力を持っていることも見て取れます。
定量結果 — 6 条件 × 4 モデル × 3 dataset
可視化だけでは判断が難しいので、定量的な裏付けとして各条件での Thm 8(a) の cosine mean を見ます。30 seed の平均値です。
| model | dataset | B1 | B2 | B3 | B4 | B5 | C5 |
|---|---|---|---|---|---|---|---|
| gemma2b | animals | -0.014 | -0.174 | -0.008 | -0.049 | -0.143 | -0.002 |
| gemma2b | emotions | -0.011 | -0.206 | -0.016 | -0.047 | -0.155 | -0.004 |
| gemma2b | nonsense | -0.008 | -0.234 | -0.005 | -0.033 | -0.154 | -0.001 |
| llama3_8b | animals | -0.006 | -0.251 | -0.018 | -0.066 | -0.168 | -0.003 |
| llama3_8b | emotions | -0.004 | -0.263 | -0.021 | -0.055 | -0.148 | -0.003 |
| llama3_8b | nonsense | -0.002 | -0.293 | -0.019 | -0.053 | -0.164 | -0.003 |
| qwen35_2b | animals | -0.011 | -0.210 | -0.011 | -0.051 | -0.140 | -0.003 |
| qwen35_2b | emotions | -0.005 | -0.235 | -0.015 | -0.044 | -0.149 | -0.003 |
| qwen35_2b | nonsense | -0.004 | -0.275 | -0.012 | -0.042 | -0.160 | -0.003 |
| llmjp4_8b | animals | -0.008 | -0.295 | -0.032 | -0.085 | -0.191 | -0.003 |
| llmjp4_8b | emotions | -0.005 | -0.288 | -0.058 | -0.064 | -0.187 | -0.002 |
| llmjp4_8b | nonsense | -0.004 | -0.313 | -0.050 | -0.081 | -0.189 | -0.002 |
この表は Park 主張に対するさまざまな角度の検証を一望できる形になっています。各条件を順に読み解いていきましょう。
B1(original)は -0.002〜-0.014 と、すべて 0 近傍。Park 主張どおり、Thm 8(a) が成り立っているように見えます。B2(random parent)は -0.17〜-0.31 と、すべての条件の中で最も大きく負にずれます。親概念をランダムにすり替えると階層直交性は確実に壊れる——という、いわば「破壊基準」に相当する値で、cosine が壊れるとどれくらいの値になるかの目安を与えてくれます。B3(シャッフル後の unembedding)は意外にも -0.005〜-0.058 と、B1とそれほど変わりません。これは「高次元空間ではランダムなベクトル同士でも cosine が 0 に近づく」性質の表れと読めます。B4(70% サブサンプル)は -0.033〜-0.085 と、B1よりやや負にずれますが、B2ほどではありません。サブサンプル単独だと、破壊効果は限定的です。B5(シャッフル + 70% サブサンプル)は -0.14〜-0.19 と、B3やB4よりはっきり大きく負に振れます。シャッフルとサブサンプルを組み合わせて初めて、trained unembedding に固有の構造が壊れるわけです。本実験で最も興味深い数字はここで、Park の追加診断がここを区別する力を持っていることを意味しています。C5(Gaussian random unembedding)は -0.001〜-0.004 と、ほぼ 0 です。学習されていないランダムな unembedding でも near-zero cosine が出てしまう——Golechha の批判の核心を直接裏付ける数字です。
要するに、表の中で対立軸となるのは B1 と C5(どちらも 0 近傍 = Golechha 派の支持)と、B4 と B5 の差(trained 構造の検出 = Park 派の支持)の二つです。
考察
Golechha-style の結果からは、一見すると相反するように見える二つの主張が、同時に成り立ちます。
第一に、raw cosine が 0 に近いことだけを意味階層の証拠として読むのは慎重であるべきです。emotions, nonsense, random unembedding でも 0 近傍の値が出てしまう以上、これは「意味階層を持たないデータでも生じる現象」と解釈する余地が大きく残ります。Golechha の批判の核心は、本実験でも明確に成り立っています。
第二に、しかし Park の診断がすべて無意味というわけでもありません。B4 と B5 の差を見るかぎり、trained unembedding とカテゴリ token set の対応関係には、シャッフルで壊れる種類の構造が確かに含まれているように見えます。ここは Park 側の議論に分があると言える部分です。
以上を踏まえると、本実験の読み方は中間的なものになります。線形表現仮説や特徴量幾何学は LLM の内部表現を語る上で有用な視点ですが、単一の cosine 指標だけで意味構造を強く主張するのは避けるべき——というあたりが、現時点での妥当な落とし所だろうと思います。
第5章. まとめ
何を見せてきたか
第 2 章で振り返ったように、LRH は十数年かけて少しずつ形を変えてきました。word2vec の king-queen 類推から始まり、線形プローブと TCAV による「方向=概念」の方法論、Reif の BERT 幾何の可視化、Transformer 時代の残差ストリーム (residual stream) への注目、Elhage の重ね合わせ (superposition) 仮説と Olsson の誘導ヘッド、Meng の ROME や Turner の活性化加算 (activation addition) による因果介入、2023 年の実証ラッシュ(Othello-GPT、Space & Time、推論時介入 (ITI)、対比一致探索 (CCS))、Cunningham・Bricken に始まり Templeton の Scaling Monosemanticity に至るスパースオートエンコーダ (SAE) の流れ、Park らの数学的形式化、Marks-Tegmark の三重証拠、Hernandez の動的拡張、Engels の弱い反例、最後に Karkada (2026) の統計的対称性からの理論的裏付け——という流れです。
その中心に位置するのが、本レポートが詳しく扱った Park 2024 と Golechha 2025 の対立です。Park は「カテゴリは多面体、階層は直交性として表現される」と踏み込み、自らの主張の自明性を切り分けるために 3 種類のコントロールを設けました。Golechha はそれに対して、emotions, nonsense, random unembedding でも Park 風の図が描けてしまうことを示し、「白色化と高次元の自明な帰結ではないか」と疑問を投げかけました。
本実験で何が分かったか
本実験では、Golechha の 3 アブレーションを 4 モデル × 30 seed で系統的に再現するとともに、Park の追加診断である B4 と B5 を初めて定量化しました。日本語モデル LLM-jp への拡張も独自に追加しています。観察された結果は、Park / Golechha の論争に対して 二つの異なる方向の証拠 を同時に提供します。
一つ目は、Golechha の批判が成り立つという方向の証拠です。B1(original)と C5(Gaussian random unembedding)の Thm 8(a) cosine がほぼ同じく 0 近傍(共に絶対値 0.02 以下)に張り付くことから、near-zero cosine だけでは意味階層に固有の証拠とは言えません。emotions(自然な階層がない)や nonsense(意味的な繋がりがない)でも同じ near-zero が出てしまう以上、Golechha の主張する「白色化と高次元の自明性」は本実験でも明確に成り立っています。
二つ目は、Park 側にもまだ分があるという方向の証拠です。B4(70% サブサンプル単独)と B5(サブサンプル + シャッフル)の差が、すべてのモデル・dataset で安定して 0.10 以上の幅で開いています(B4 は -0.03〜-0.09、B5 は -0.14〜-0.19)。これは「シャッフルで壊れる種類の構造が trained unembedding に残っている」ことを示唆しており、Park の追加診断は完全に自明な artifact ではありません。
そして、これら二つの観察が 4 モデル(英語 3 + 日本語 LLM-jp)すべてで一貫して再現される点は、特定モデルや特定言語に依存しない普遍的な現象であることを示します。Park の英語のみの実験を日本語に拡張しても同じ傾向が見える、という事実は、本実験のささやかな貢献として残しておきたいところです。
これからの問い
最も興味深い宿題は、B4 と B5 の差が何を捉えているか、です。trained unembedding には、シャッフルで壊れる種類のどんな構造が残っているのか——それを直接特徴付ける指標は、まだ我々の手元にはありません。Karkada (2026) の言う「言語データの統計的対称性」の枠組みでこの差をどう説明できるかは、本実験から自然に出てくる次の問いです。
進めるべき方向として、いくつか挙げておきます。
- full WordNet 条件での全アブレーション: 本実験は flat dataset (animals/emotions/nonsense) で B1〜C5 を比較しましたが、WordNet 全体でも同じアブレーションを行えば、階層の深さによる差を見ることができます。
- cosine 以外の幾何指標: angular distribution、anisotropy、effective rank などとの併用で、cosine 単独では見えない構造の違いが浮かび上がる可能性があります。
- 挙動への介入実験との組み合わせ: 図や数値が「見える」段階から、それがモデルの実際の振る舞いを動かしているかを確かめる段階へ。本実験は「見えるか」までで止まっていますが、最終的には「効くか」の検証が必要です。
読者への持ち帰り
最後に、本レポートを通じて持ち帰っていただきたい 3 点を整理します。
1 つ目は、LRH は LLM の内部を語る共通語彙として確かに有用だ、ということ。SAE や表現エンジニアリング (representation engineering) といった interpretability の現代ツールはみな LRH を土台にしており、これを抜きに LLM の中を議論するのは難しくなっています。
2 つ目は、図や cosine が美しく見えることと、意味構造が因果的に表現されていることは別物だ、ということ。高次元空間ではランダムでも near-zero cosine や simplex 風の見た目は出てしまうので、単一指標だけで強い主張をするのは危険——というのは、本実験の B1 vs C5 の比較から改めて確認できました。
3 つ目は、それでも完全な reduction は早すぎる、ということ。本実験の B4 と B5 の差のように、シャッフルで壊れる種類の構造は確かに観察されます。Park 側の議論をすべて自明な artifact だと片付けるには、まだ説明されていないものが残っています。
LRH をめぐる議論は、Park と Golechha のどちらに傾くかではなく、「どんな構造がどこまで言えて、どこから疑うべきか」を細かく切り分けていく作業の途上にあります。本実験がその切り分けの一部として、誰かの参考になれば幸いです。
参考文献
- Alain, G., & Bengio, Y. (2017). Understanding intermediate layers using linear classifier probes. ICLR 2017 Workshop.
- Bricken, T., Templeton, A., Batson, J., Chen, B., Jermyn, A., Conerly, T., et al. (2023). Towards monosemanticity: Decomposing language models with dictionary learning. Anthropic Transformer Circuits Thread.
- Burns, C., Ye, H., Klein, D., & Steinhardt, J. (2023). Discovering latent knowledge in language models without supervision. ICLR 2023.
- Cunningham, H., Ewart, A., Riggs, L., Huben, R., & Sharkey, L. (2023). Sparse autoencoders find highly interpretable features in language models. ICLR 2024.
- Elhage, N., Hume, T., Olsson, C., Schiefer, N., Henighan, T., Kravec, S., et al. (2022). Toy models of superposition. Anthropic Technical Report.
- Engels, J., Liao, I., Michaud, E. J., Gurnee, W., & Tegmark, M. (2024). Not all language model features are one-dimensionally linear. ICLR 2025.
- Golechha, S., Bushnaq, L., Ong, J., Kayal, A., & Schoots, N. (2025). Intricacies of feature geometry in large language models. ICLR Blogposts.
- Gurnee, W., & Tegmark, M. (2023). Language models represent space and time. ICLR 2024.
- Hernandez, E., Sharma, A. S., Haklay, T., Meng, K., Wattenberg, M., Andreas, J., et al. (2024). Linearity of relation decoding in transformer language models. ICLR 2024 Spotlight.
- Hewitt, J., & Manning, C. D. (2019). A structural probe for finding syntax in word representations. NAACL 2019.
- Karkada, D., Korchinski, D. J., Nava, A., Wyart, M., & Bahri, Y. (2026). Symmetry in language statistics shapes the geometry of model representations. arXiv:2602.15029.
- Kim, B., Wattenberg, M., Gilmer, J., Cai, C., Wexler, J., Viegas, F., & Sayres, R. (2018). Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (TCAV). ICML 2018.
- Li, K., Hopkins, A. K., Bau, D., Viégas, F., Pfister, H., & Wattenberg, M. (2023a). Emergent world representations: Exploring a sequence model trained on a synthetic task (Othello-GPT). ICLR 2023.
- Li, K., Patel, O., Viégas, F., Pfister, H., & Wattenberg, M. (2023b). Inference-time intervention: Eliciting truthful answers from a language model. NeurIPS 2023.
- Marks, S., & Tegmark, M. (2024). The geometry of truth: Emergent linear structure in large language model representations of true/false datasets. COLM 2024.
- Meng, K., Bau, D., Andonian, A., & Belinkov, Y. (2022). Locating and editing factual associations in GPT (ROME). NeurIPS 2022.
- Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space. ICLR Workshop.
- Olsson, C., Elhage, N., Nanda, N., Joseph, N., DasSarma, N., Henighan, T., et al. (2022). In-context learning and induction heads. Anthropic Transformer Circuits Thread.
- Park, K., Choe, Y. J., & Veitch, V. (2023). The linear representation hypothesis and the geometry of large language models. ICML 2024.
- Park, K., Choe, Y. J., Jiang, Y., & Veitch, V. (2024). The geometry of categorical and hierarchical concepts in large language models. ICLR 2025.
- Pennington, J., Socher, R., & Manning, C. D. (2014). GloVe: Global vectors for word representation. EMNLP 2014.
- Reif, E., Yuan, A., Wattenberg, M., Viégas, F. B., Coenen, A., Pearce, A., & Kim, B. (2019). Visualizing and measuring the geometry of BERT. NeurIPS 2019.
- Templeton, A., Conerly, T., Marcus, J., Lindsey, J., Bricken, T., Chen, B., et al. (2024). Scaling monosemanticity: Extracting interpretable features from Claude 3 Sonnet. Anthropic Transformer Circuits Thread.
- Turner, A., Thiergart, L., Udell, D., Leech, G., Mini, U., & MacDiarmid, M. (2023). Activation addition: Steering language models without optimization. arXiv:2308.10248.


